Hi everyone, I built a fuel cell model and got some sensitive parameters for that model by calculating sensitivity coefficients. The model can be simplified as Current = f_model(potential).
Now I want to get the posterior PDFs of these sensitive parameters based on a set of experiment data (potential-current).
Firstly I defined a f_model(theta,data) function
def current(theta,data): ***#theta is sensitive parameters, data is the experiment data of current***
potential = [0.01629, 0.12868,0.2325, 0.34037, 0.45276, 0.57327] #the experiment data of potential
... ***#based on different potential I got different curr (simulation results)***
sigma = 0.5
logp = -len(data)*np.log(np.sqrt(2.0 * np.pi) * sigma)
logp += -np.sum((data[k]*1000 - curr*0.1)** 2.0) / (2.0 * sigma ** 2.0)
return logp ***#then I defined a likelihood function. ***
the rest code are:


Feel sorry that it may be hard to rebuild my code because my model depend on many python libraries.
When I set a single pair of potential-current like potential = [0.01629] current data = np.array([0.00882])
result is:

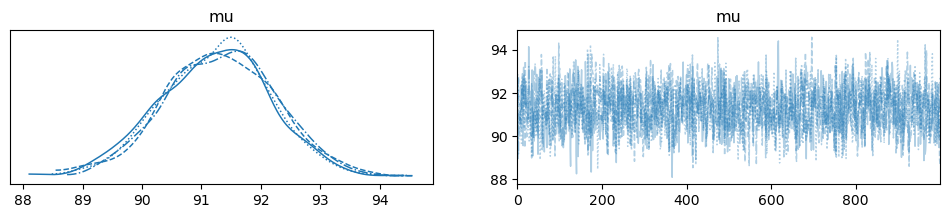
when I set potential = [0.01629, 0.12868,0.2325, 0.34037, 0.45276, 0.57327] current data = np.array([0.00882, 0.09581, 0.19992,0.29675, 0.38142, 0.47337])
result is:

The relationship between potential and current is :

test is experiment data I used in code and simulation is unoptimized model simulation.
- If I just sample one parameter based on one experiment point like potential = [0.01629] current data = np.array([0.00882]) the posterior PDFs seems good. So I think there maybe no code bug?
- If I sample four parameters based on one experiment or all experiment points. The results are really abnormal.
Really appreciated for any advice. ![]()