Hi,
I am trying to convert the trace in to a dataframe. I used to use
file_read_in= trace.to_dataframe(groups = “posterior”, include_coords = False) but it seems to_dataframe does not work with multitrace object.
I tried now with the following code -
file_read_in=az.from_pymc3(trace=trace).to_dataframe(include_coords=False)
this creates a dataframe which has word “posterior” and quotes"()" in the variable name -
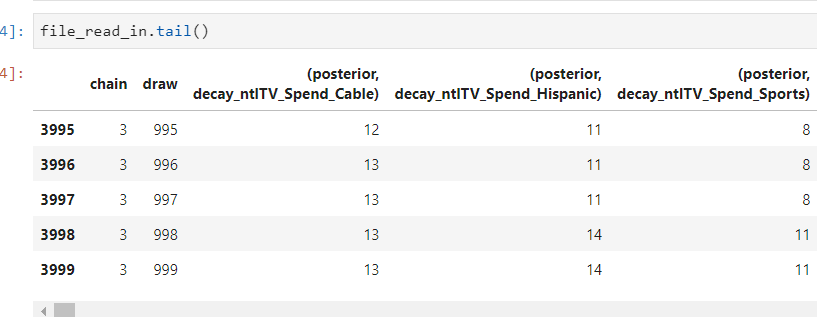
This is not letting me filter for specific variables in the dataframe when I try to transpose and filter -
df_sum_parts= pd.melt(file_read_in, id_vars = ['chain', 'draw'], var_name = 'var_name', value_name = 'value')
df_sum_parts= df_sum_parts[df_sum_parts['var_name'].str.contains('decay_')]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/tmp/ipykernel_322/2409040180.py in <module>
1 #df_sum_parts = pd.melt(file_read_in, id_vars = ['chain', 'draw'], var_name = 'var_name', value_name = 'incr_items')
----> 2 df_sum_parts = df_sum_parts[df_sum_parts['var_name'].str.contains('decay_')]
3 df_sum_parts.tail()
/opt/conda/lib/python3.8/site-packages/pandas/core/frame.py in __getitem__(self, key)
3509 if is_iterator(key):
3510 key = list(key)
-> 3511 indexer = self.columns._get_indexer_strict(key, "columns")[1]
3512
3513 # take() does not accept boolean indexers
/opt/conda/lib/python3.8/site-packages/pandas/core/indexes/base.py in _get_indexer_strict(self, key, axis_name)
5780 keyarr, indexer, new_indexer = self._reindex_non_unique(keyarr)
5781
-> 5782 self._raise_if_missing(keyarr, indexer, axis_name)
5783
5784 keyarr = self.take(indexer)
/opt/conda/lib/python3.8/site-packages/pandas/core/indexes/base.py in _raise_if_missing(self, key, indexer, axis_name)
5840 if use_interval_msg:
5841 key = list(key)
-> 5842 raise KeyError(f"None of [{key}] are in the [{axis_name}]")
5843
5844 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
KeyError: "None of [Float64Index([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,\n ...\n nan, nan, nan, nan, nan, nan, nan, nan, nan, nan],\n dtype='float64', length=39424000)] are in the [columns]"
Could someone please tell me the way to convert trace to a pandas dataframe and then use filtering techniques like the one mentioned above?