I am estimating a hierarchical Bayesian model using two model specifications with minor change in the functional form. I use \theta inside F(x;\cdot) in Specification 1 while \theta' in 2, where \theta and \theta' are fixed hyperparameters and are close to each other (i.e., \theta - \theta' <\delta where \delta is very small).
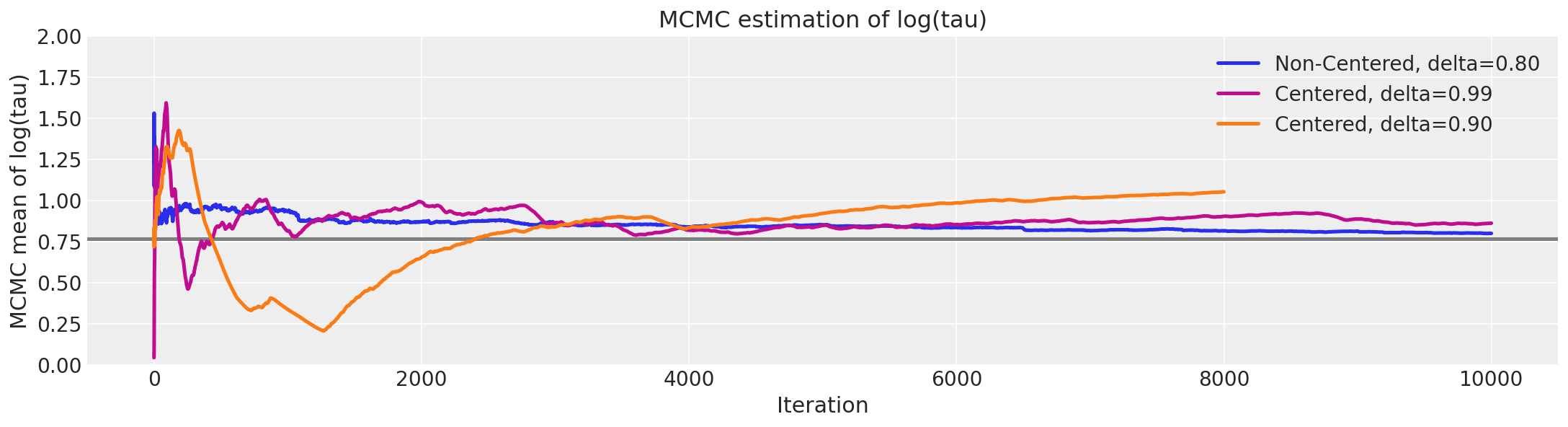
As for model results, I find r_hat for all estimates from both specifications are great (close to 1). When comparing trace plots (generated by az.plot_trace) for const_j and \epsilon, I find estimates are close in values (or magnitudes) but the cases of data divergences indicated by dashed vertical lines in the trace plots are different! (see pictures below)
Questions:
How to understand the data divergences in the trace plots?
Why do I see such a big difference in the presence of data divergences in the trace plots while not the estimate values?
Do these data divergences suggest using \theta is better than \theta'?
How to understand the data divergences
Specification 1 (j is indexed for area, t for time)
I would suggest checking out the notebook on diagnosing divergences. Inspecting the traceplots can sometimes help, but often a deeper dive is needed to really figure out what is causing divergences.
Thanks for sharing this post. I have gone through it. There are three takeaways:
Increase the length of the chain (i.e., increase the number of draws)
Decrease the step size (i.e., increase the target_accept parameter)
Reparameterize coefficients of interest
I have used the reparameterization trick with sufficient draws (in my case, draws=4000 and chains=4). But I haven’t tried decreasing the step size yet. Will do.
Does the chart at the end suggest that reparameterization (“non-centered” line) leads us to the converged value of the estimate faster than the original parameterization with a smaller step size (mauve “centered” line, target_accept=0.99)?
Increasing the number of draws and adjusting the target acceptance rate are options to help fix minor sampling issues. But to really diagnose what is going on, those approaches aren’t going to help. The plots here and here illustrate one approach that help to figure out why and where your model may be generating those divergences.
Yes. Also, a target acceptance rate of .99 is extremely high and, if necessary to eliminate divergences, suggests something is faulty with the model (e.g., in need of respecification).
The fact that the non-centered specification yields decent sampling with a target acceptance of 0.8 suggests that it is relatively high (high ESS/draw).
Arviz just plots the diagnostics that are generated during sampling. When a divergence occurs, the sampler logs it in the inferenceData object. If you want to know what a divergence is more precisely, I would recommend Michael Bettencourt’s A Conceptual Introduction to Hamiltonian Monte Carlo.
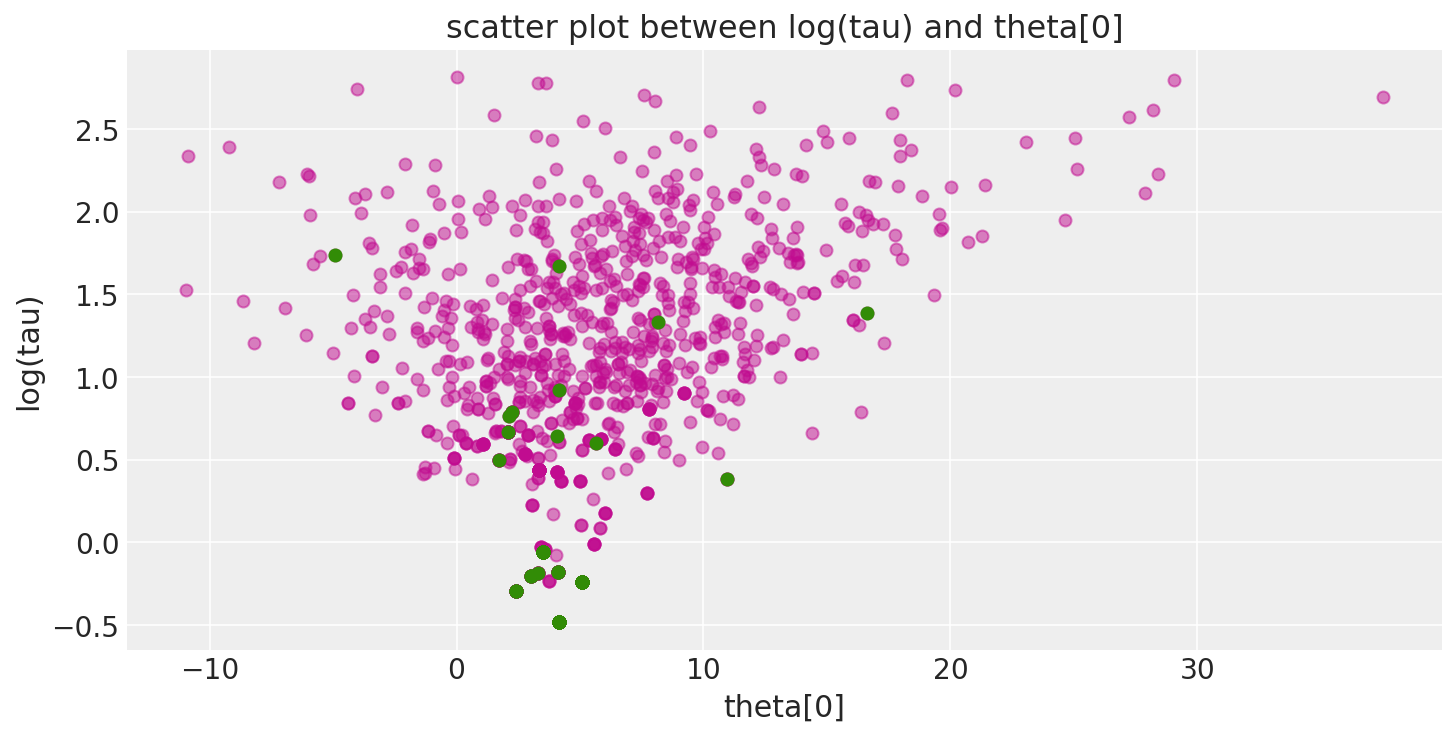
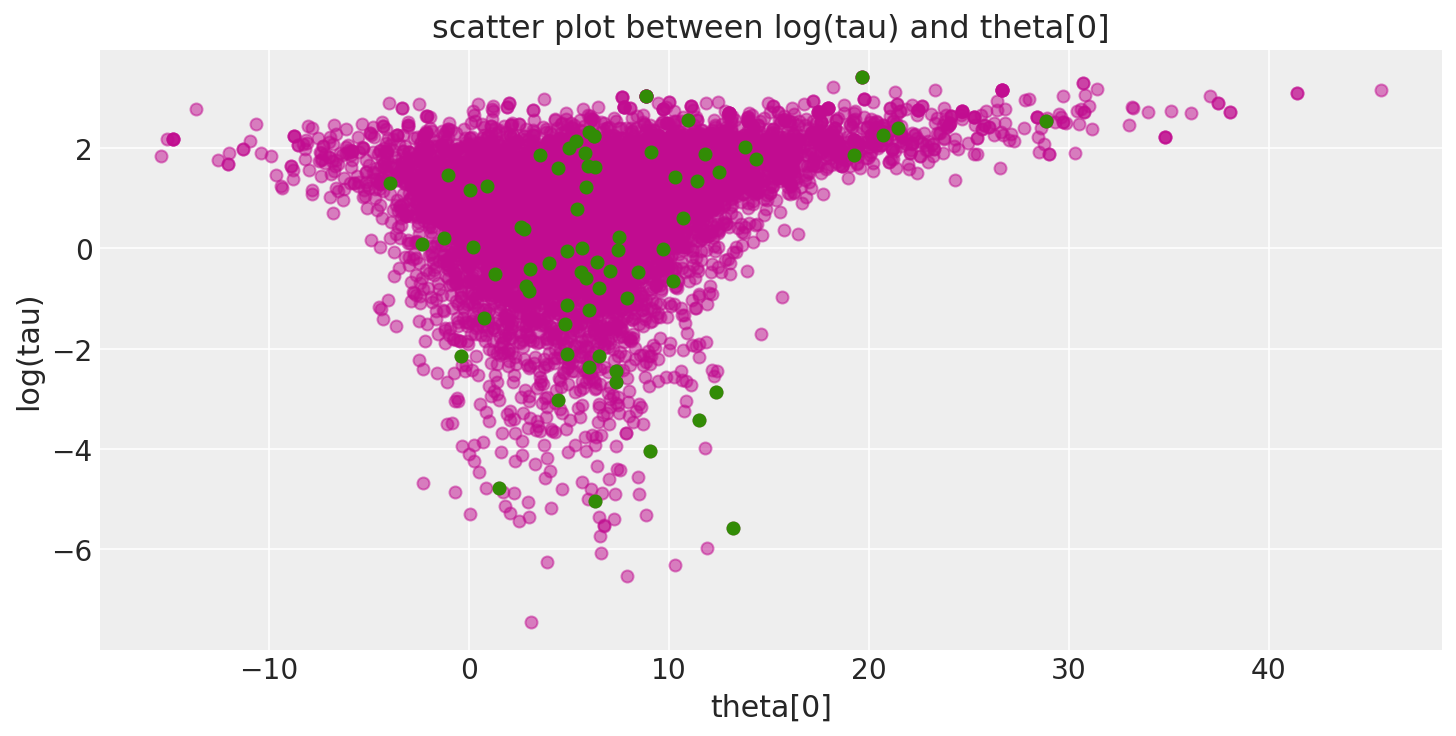
Thanks for pointing out these two plots that can help identify where we see these divergences. Comparing Figure 1 to 2, we can say log(tau) might have a convergence issue when it is small, approaching 0 (divergences–green dots–appear in the place around 0). What else can we read from Figure 2?
Since the green dots in Figure 2 do not show us a clear pattern of concentration or anything else, can we simply remove them from the trace data stored in the az.InferenceData and use the az.InferenceData without divergences to do further posterior inference?
The fact that the non-centered specification yields decent sampling with a target acceptance of 0.8 suggests that it is relatively high (high ESS/draw).
ESS is a number indicating the efficiency of an algorithm. In general, is high ESS/draw a bad signal?
If you read through that notebook, you will see that the green dots (particularly in the first plot) are concentrated at the neck of a “funnel” and it is that funnel that is a) problematic for the sampler and b) helped once the model is respecified.
ESS captures the amount of “information” in a chain (a set of draws). So high ESS is what you want and high ESS per draw means your sampling is efficient (and thus good).






{kind=link}
{kind=link}