Hello,
Let´s say I have a dataset where I can observe 10 inputs when creating it, but when I will use the model for prediction on real cases, I will just have 2 of these inputs, the other 8 their distributions are known for the whole dataset but can not be certain for each sample.
I am wondering what would be an appropriate approach to increase the posterior predictive variance to account for this uncertainty. One thought is that I can follow a frequentest approach, using all the 10 inputs to train the model, then when using it for prediction, for each single prediction, the 2 known inputs will be fixed, while the other 8 will be sampled from a Monte Carlo simulation and then output the distribution of the prediction. But I would rather approaching this problem from the Bayesian paradigm, so here are my thoughts.
First I can not include the uncertain inputs in this way, following my previous question, because this mean I will have a parameter for each data sample. I want to make these uncertain inputs shared between all the samples, just like the covariance function parameters.
Another approach would be to include them in the mean function as coefficients, and using their known distributions as priors, but to my understanding, for example if I am using a linear function, I will need to find a way to make them coefficients of the known 2 inputs, which may not be optimal, neither represent the fact that they are independent variables just like the other 2 inputs, so they should not depend on these 2 inputs.
If include all the 10 inputs in a regular way, I get good prediction, and the true value is inside the 95 % credible intervals, which is my goal, however I think this is biased, because in reality we will not have all the inputs available for predictions. for example in this image I am including some of the important unknown inputs in the training.

while here I am just training on the 2 known inputs, my problem is that I want to find a way to increase the uncertainty in the prediction so I more or less make sure that most of the time, the actual value lives in the credible interval, and I also want to avoid going to the frequentest approach.
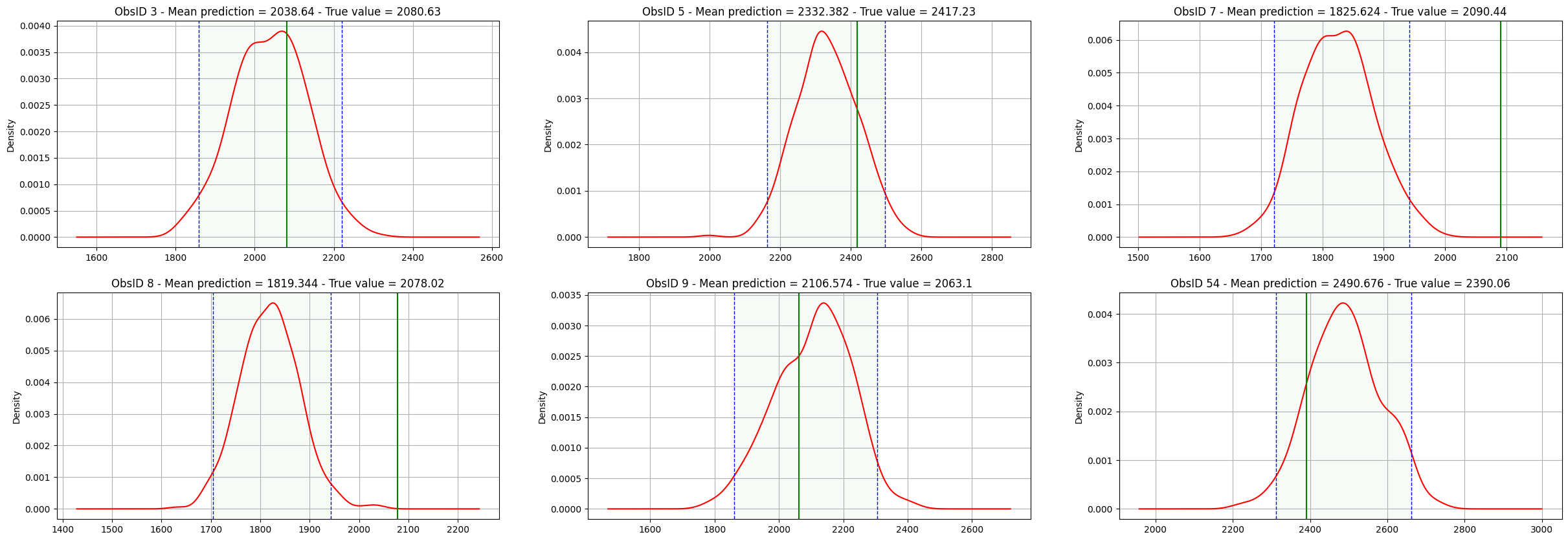
So, in short, is there a way I can have the 8 unknown inputs (they have 8 known distributions) as shared parameters between all the data points while treating them as independent variables, just like the 2 known inputs?