Hi everyone,
I’ve been using PyMC3 with NUTS for quite a large hierarchical model. A few features of the model/inference:
- there are approximately 4000 observations.
- there are a large number of latent variables, approximately 8000.
- the purpose of the model is to infer a small number of these latent variables (10). There are weak correlations in the posterior (correlation coefficients ~0.4) in this reduced set of variables.
- on my local machine, profiling the model takes ~1.5 seconds for 1000 evaluations of
model.logpt - using normal priors, with negative binomial output distributions.
- the first few 1000 samples or so (during tuning) are very fast, and then it slows down significantly.
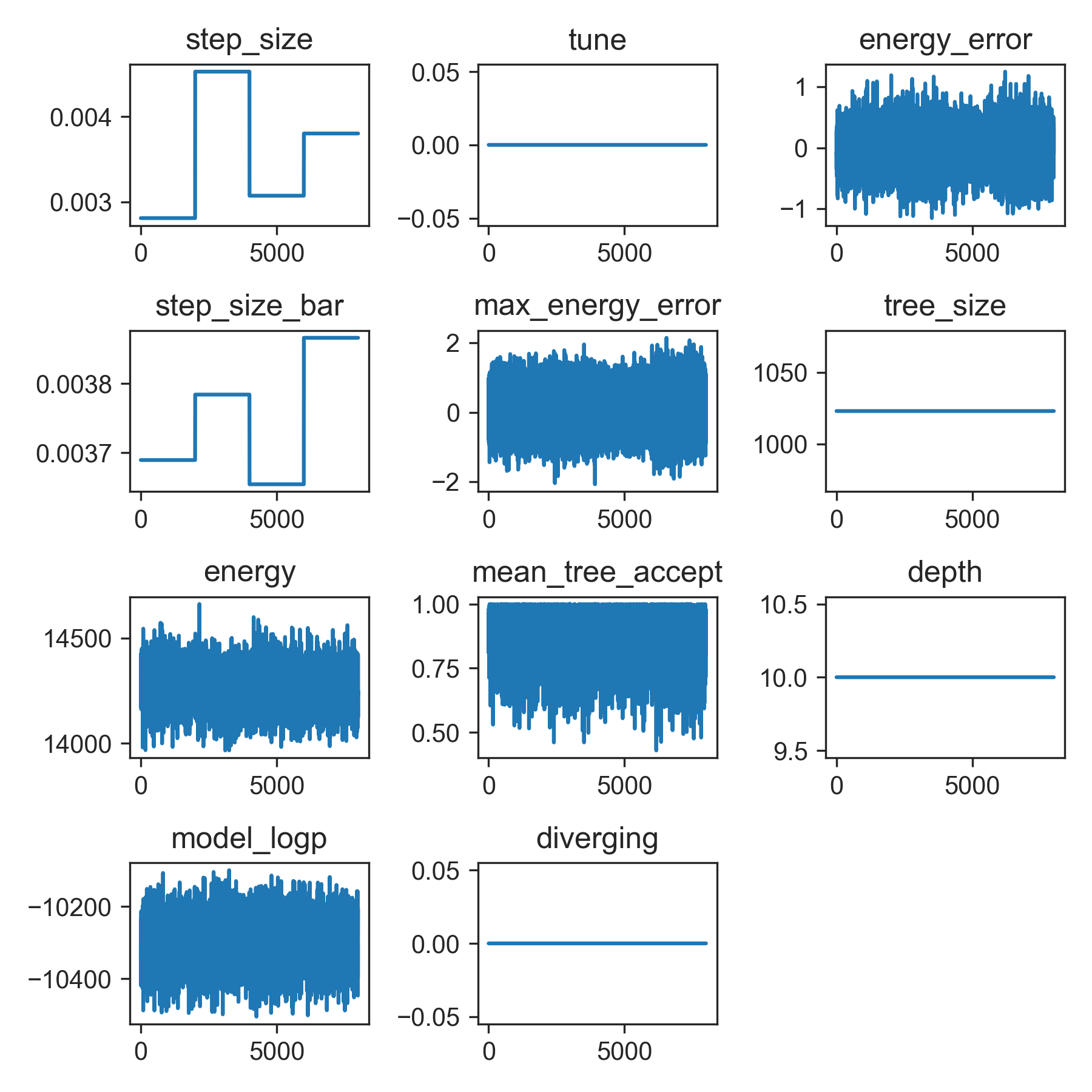
The performance I get with this model is that 12000 samples (4000 + 8000 samples, across four chains) takes about 5 hours. I’m not sure if this runtime is to be expected when the model is this large, but it would be great to see if it can be reduced. The model itself seems to be running fairly fast, but the performance of NUTS is bad. I’ve attached plots of the sampler statistics, but I don’t know how to interpret them very well.
The typical advice that I see is that re-parameterise the model, especially to avoid ‘funnels’ with scale hyperparameters. I don’t think that my model has these hyperparameters. I’m not sure how else to try and optimise the model, and because there are such a large number of parameters, I’m not sure how to investigate what is causing the long runtime (e.g., computing pairwise plots for all values would give a huge number of plots!).
I looked into trying the experimental jitter+adapt_full NUTS initialisation, but I found that performance for this was actually significantly worse (which I’m surprised by).
Model code: CM_Combined_Final Class, Github Link
One option would be to manually set the mass matrix myself using a posterior trace that I have. I don’t actually know how to do this, and whether this would give a big improvement.
Thanks