Hi,
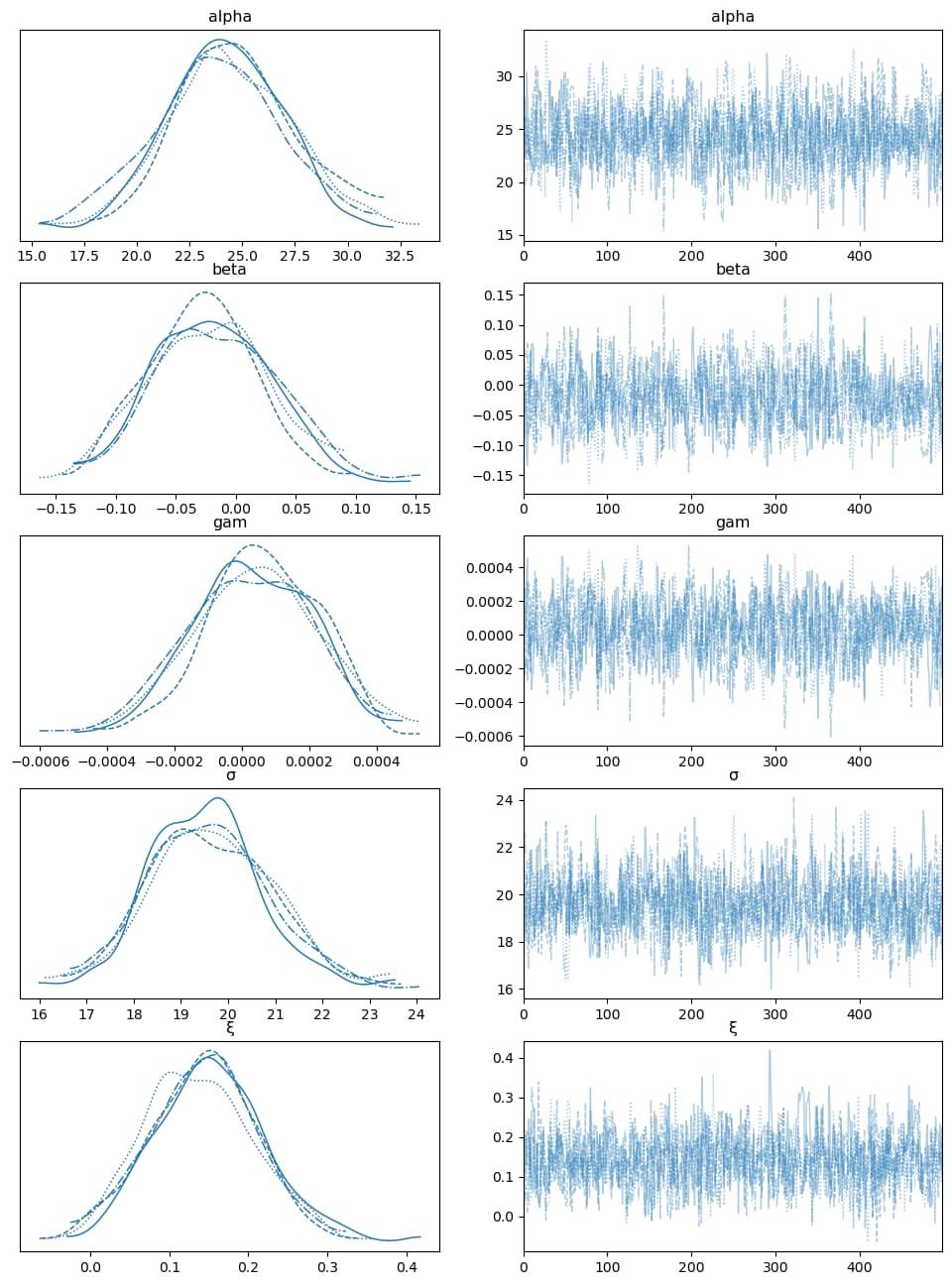
I am quite new to Bayesian Liner regression. I want to perform linear regression using Generalized extreme value (GEV) distribution. My code is working well while trying to estimate the three parameters of GEV. However, I am getting wrong values when I am assuming the location parameter (mu) as a function of time to account for nonstationary. The rhat statistics is larger than 1.01 for all the parametrs and I am getting a single value.
Below is my code:
X = np.linspace(1, 276, 276)
X = X.astype(int)
df1 = pd.read_csv('Datapy.csv')
[Datapy.csv|attachment](upload://ladV0IWHHMafHpK7VjaaOU6CzRh.csv) (2.1 KB)
###################################
with pm.Model() as model:
# Priors
alpha =pm.Normal('alpha', 0, 100)
alpha = alpha.astype(int)
beta = pm.Normal('beta', 0, 100)
beta = beta.astype(int)
gam = pm.Normal('gam', mu=0.0, sigma=100.0)
gam = gam.astype(int)
σ = pm.HalfNormal("σ", sigma=21)
ξ = pm.Normal("ξ", mu=0.0, sigma=0.35)
# Expected value of outcome
μ = alpha + beta*X +gam*X^2
# Estimation
gev = pmx.GenExtreme("gev", mu=μ, sigma=σ, xi=ξ, observed=df.r)
#####################################################################
idata = pm.sample_prior_predictive(samples=1000, model=model)
az.plot_ppc(idata, group="prior", figsize=(12, 6))
ax = plt.gca()
az.plot_posterior(
idata, group="prior", var_names=["alpha", "beta","gam","σ", "ξ"], hdi_prob="hide", point_estimate=None
);
######################################################
with model:
trace = pm.sample(
500,
cores=4,
chains=4,
tune=2000,
initvals={'alpha':0.92, 'beta': -2.5, "gam": 0.9, "σ": 1.0, "ξ": -0.1},
target_accept=4,
)
I have uploaded the data if you want to try. Any help would be greatly appreciated.
Thanks,
Alok