Hi, there have been a few questions about the LogNormal already, but I feel nothing as straightforward as this:
import pytensor.tensor as pt
import pymc as pm
s, loc, scale = 0.94, -32, 152 # from a scipy fit
with pm.Model() as model:
# q = pm.Uniform("ais", lower=loc, upper=1000) # this converges fine
q = pm.Uniform("ais", lower=loc-10, upper=1000) # this doesn't !
q = pt.clip(q, loc+1e-9, 1e9)
log_lik = lambda x: pm.logp(pm.Lognormal.dist(mu=np.log(scale), sigma=s), x-loc)
pm.Potential("constraint", log_lik(q))
trace = pm.sample()
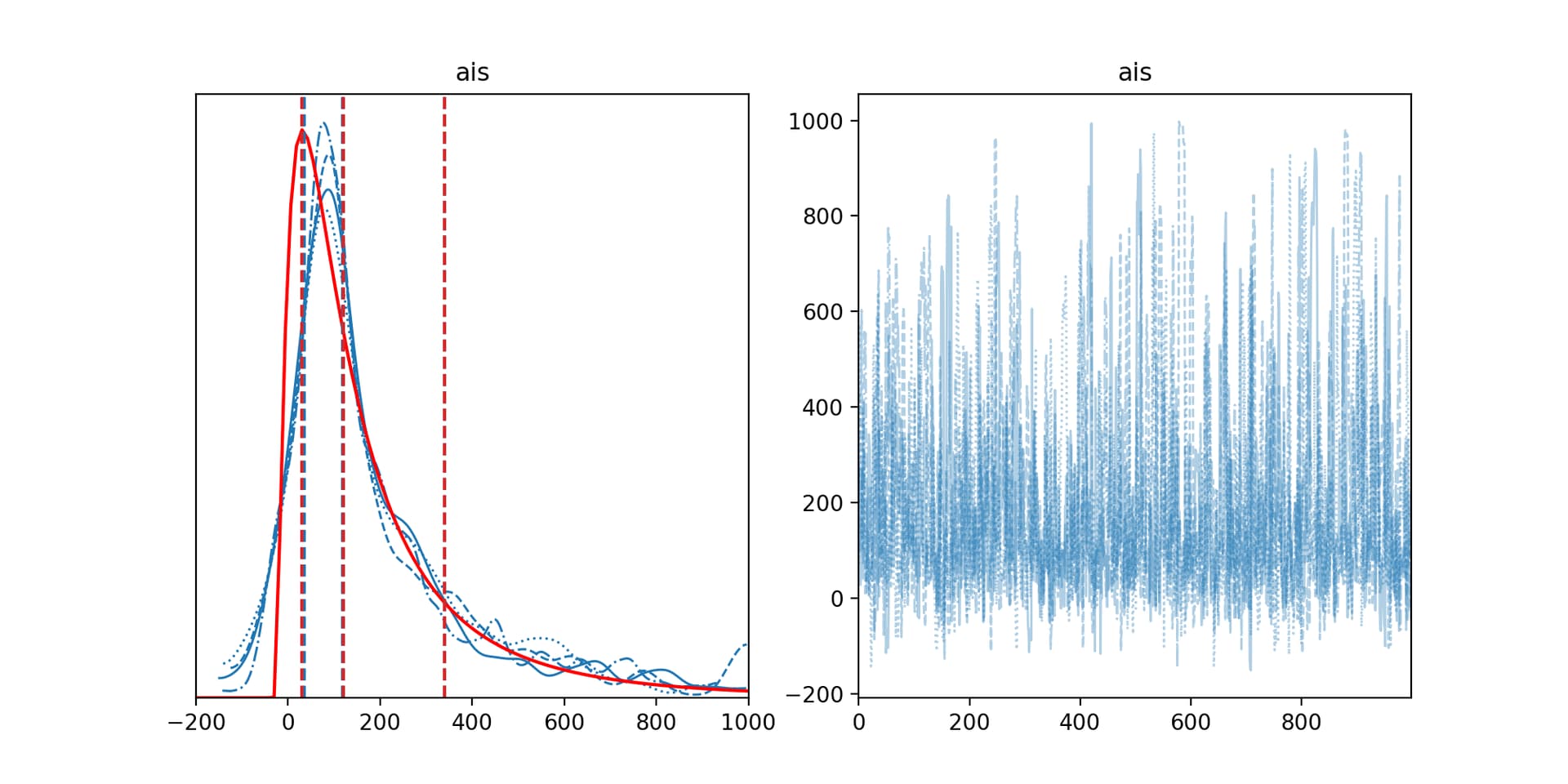
As long as I stay strictly in the definition domain of the lognormal, this converges fine, otherwise, it does not (the example above has about 120 divergences on four chains). In my real model, the q parameter is the result of a more complex calculation and cannot be chosen as it pleases the sampler. I’d just like to assign the probability of going there something small, close to zero when less than the threshold, and lognormal otherwise. I tried to transform q in various ways besides clip, to no avail. Any idea how to achieve this?
PS: the result looks OK, but the convergences are not a good sign nonetheless
import arviz as az
from scipy.stats import lognorm
axes = az.plot_trace(trace)
x = np.linspace(*axes[0, 0].get_xlim(), 100)
dist = lognorm(s, loc=loc, scale=scale)
y = dist.pdf(x)
axes[0, 0].plot(x, y, "r")