Dear pymc experts,
I am trying to compare two sets of donation data that were generated in a A/B test. The values are donation income (revenue).
data = [120.0, 500.0, 0.01, 40.0, 1000.0, 150.0, 1500.0, 13.0, 200.0, 3000.0, 200.0, 45.0, 221.0, 20.0, 100.0, 60.0, 400.0, 20.0, 250.0, 60.0, 100.0, 60.0, 30.0, 120.0, 40.0, 60.0, 100.0, 1500.0, 450.0, 1.0, 250.0, 200.0, 100.0, 100.0, 300.0, 120.0, 45.0, 120.0, 200.0, 150.0, 120.0, 50.0, 201.0, 50.0, 200.0, 200.0, 50.0, 200.0, 1.1, 80.0, 1400.0, 20.0, 50.0, 250.0, 60.0, 60.0, 60.0, 150.0, 20.0, 100.0, 120.0, 20.0, 550.0, 45.0, 250.0, 250.0, 15.0, 60.0, 300.0, 20.0, 30.0, 400.0, 200.0, 60.0, 400.0, 500.0, 30.0, 50.0, 250.0, 50.0, 5.0, 1.0, 1.0, 50.0, 50.0, 100.0, 120.0, 60.0, 5.0, 5.0, 30.0, 30.0, 60.0, 15.0, 50.0, 100.0, 200.0, 100.0, 100.0, 50.0, 100.0, 50.0, 50.0, 550.0, 75.0, 100.0, 250.0, 20.0, 1000.0]
idx = [0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
I have tried to model the data using a lognormal distribution, which ran without divergences.
with pm.Model() as model:
µ_log = pm.Normal('µ_log', mu = 0, sigma = 2, shape = groups)
sigma = pm.HalfNormal('sigma', sigma = 4, shape = groups)
y_hat = pm.Lognormal('y_hat', mu = µ_log[idx], sd = sigma[idx], observed = data)
µ = pm.Deterministic('µ', np.exp(µ_log))
mode_log = pm.Deterministic('mode_log', µ_log - sigma ** 2)
mode = pm.Deterministic('mode', np.exp(mode_log))
median = pm.Deterministic('median', np.exp(µ_log))
diff_of_modes = pm.Deterministic('diff of modes', mode[1] - mode[0])
diff_of_median = pm.Deterministic('diff of median', median[1] - median[0])
trace = pm.sample(10000, tune = 10000)
ppc = pm.sample_posterior_predictive(trace, samples = 20000, model = model, var_names=['µ','µ_log', 'y_hat', 'mode'])
pm.traceplot(trace)
However I noticed, that the estimated mode does not seem to reflect the data very well. I would have expect the most likely values for the mode to be 50 or 100, however the modes are well below that.


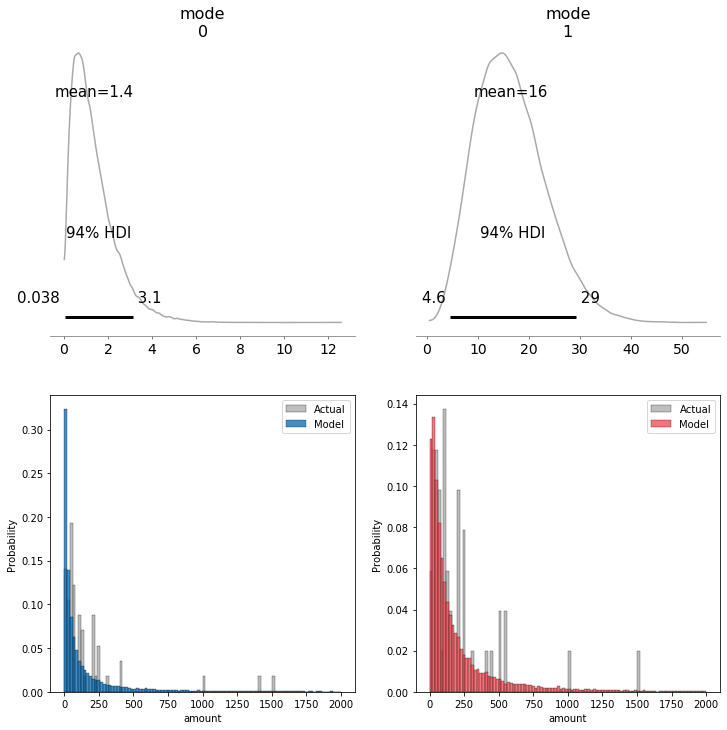
Do you have any suggestions on how I could improve this model? Can you spot any errors in my code or thought process?





