I have a question re: posterior checks:
I fit two versions of a hurdle-gamma model, Fit1 and Fit2. The LOO compare looks like this:

Fit2 seems to be a better fit. However, when I look at the PPC plots, I get this:
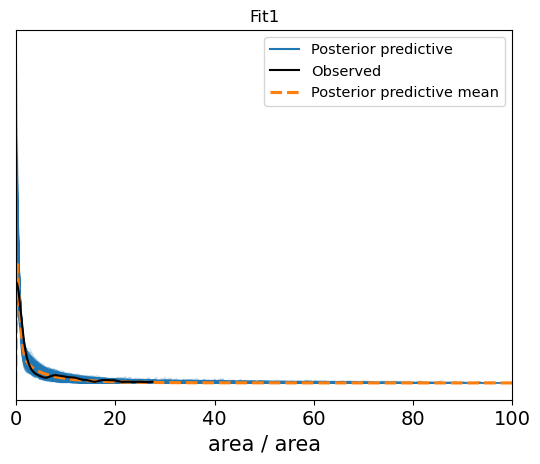

The posterior predictive looks good in both cases but Fit2 seems to fit a little better. However, the posterior predictive mean seems worse in Fit2 vs Fit1. Given the hurdle, does that matter, given the better LOO for Fit2?
Thanks for your kind attention.