I am fairly new to PyMC3 and I am trying to model the uncertainty propagation during the calibration process of a sensor. As such, the outputs of my model are [Y] and the inputs are [X]. xdata and ydata are the np.arrays containing my calibration data. My model looks` like this:
def volt_est(w,x):
return w[0] + w[1]*(1/x) + w[2]*(1/(x**2)) + w[3]*(1/(x**3)) + w[4]*(1/(x**4))
with pm.Model() as model:
sigma2_w = pm.Exponential('sigma2_w',lam=0.5, shape=5)
w = pm.Normal('w', mu=0, sigma=sigma2_w, shape=5)
# Input uncertanty
x = pm.Normal('x', mu=xdata, sigma=10., shape=xdata.shape[0], testval=xdata)
# Data Likelihood
x_like = pm.Normal('xdata', mu=x, sigma=0.0025, observed=xdata)
likelihood = pm.Normal('y', mu=volt_est(w,xdata), sigma=0.05, observed = ydata)
When I sample from the posterior I get the distributions for my weights ‘w’:
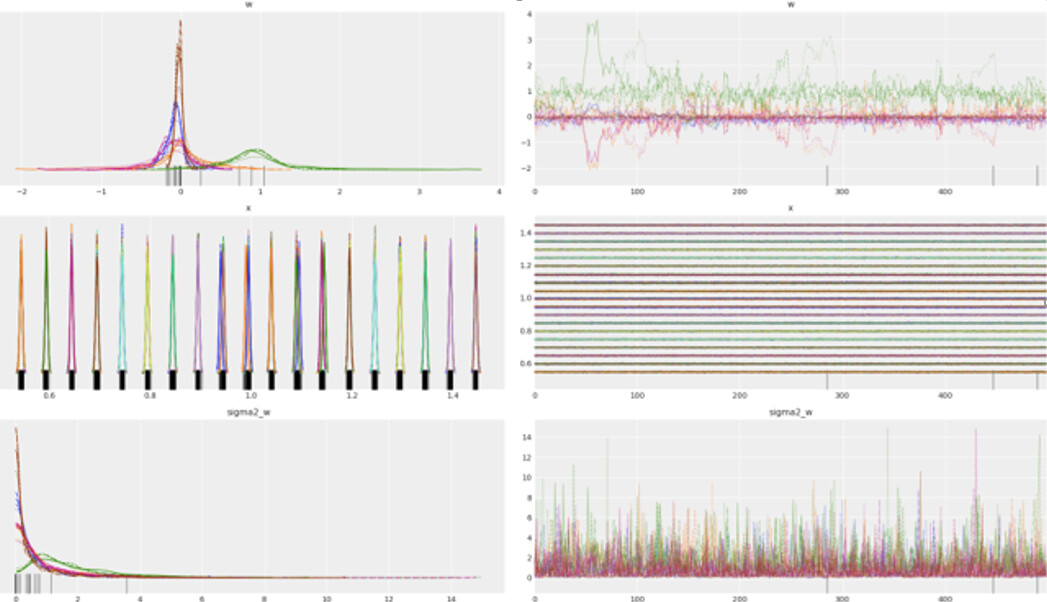
During an actual experiment, I am interested in retrieving an expectation and standard deviation for variable X based on a voltage input, Y. How can I do this?
I tried making X and Y shared variables, then setting the value of Y to my observed experiment value and finally, sample from the posterior to retrieve X but it did not work. Any thoughts?
Thank you!


