I am trying to build the following model:

With some of the sampled data looking like the following:
N = 100000
x = 2*np.random.rand(N,1) - 1
idx = np.random.rand(N) < 0.5
y = 3*x
y[idx] = -x[idx]
y = y + 0.1*np.random.randn(N,1)

The pymc3 model looks like following and I sample it using minibatches for Variational Bayes (so that avoid/ minimise label switching).
def logp_normal(mu, sigma, value):
# log probability of individual samples
delta = (value - mu).ravel()
k = delta.shape[0]
return -0.5 * (k * tt.log(2 * np.pi) + tt.log(sigma) + tt.square(delta).sum()/tt.square(sigma))
# Log likelihood of Gaussian mixture distribution
def logp_gmix(mus, pi, sigma):
def logp_(value):
logps = [tt.log(pi[i]) + logp_normal(mu, sigma, value) for i, mu in enumerate(mus)]
return tt.sum(pm.math.logsumexp(tt.stacklists(logps), axis=0))
return logp_
K = 2 #components
D = 1 #dimensionality of x
X = theano.shared(x)
Y = theano.shared(y.ravel())
with pm.Model() as model:
pi = pm.Dirichlet('pi', np.ones(K))
ws = [pm.Normal('w_%d'%i, mu=0, sd=2, shape=(D,)) for i in range(K)]
sigma = pm.Uniform('sigma', 0, 1)
mus = [tt.squeeze(tt.dot(X,w)) for w in ws]
y_obs = pm.DensityDist('y_obs', logp_gmix(mus, pi, sigma), observed=Y)
With the inference part looking like:
batch_size = 128
X_m = pm.Minibatch(x, batch_size)
Y_m = pm.Minibatch(y.ravel(), batch_size)
with model:
approx = pm.fit(10000,
more_replacements={X:X_m, Y:Y_m},
callbacks=[pm.callbacks.CheckParametersConvergence(tolerance=1e-4)],
method='fullrank_advi')
# Sample from the posterior
n = 1000
trace = approx.sample(n)
However, when I look at the posteriors unfortunately of the trace, it doesn’t seem to be able to converge on the weights (3 and -1 in our case).
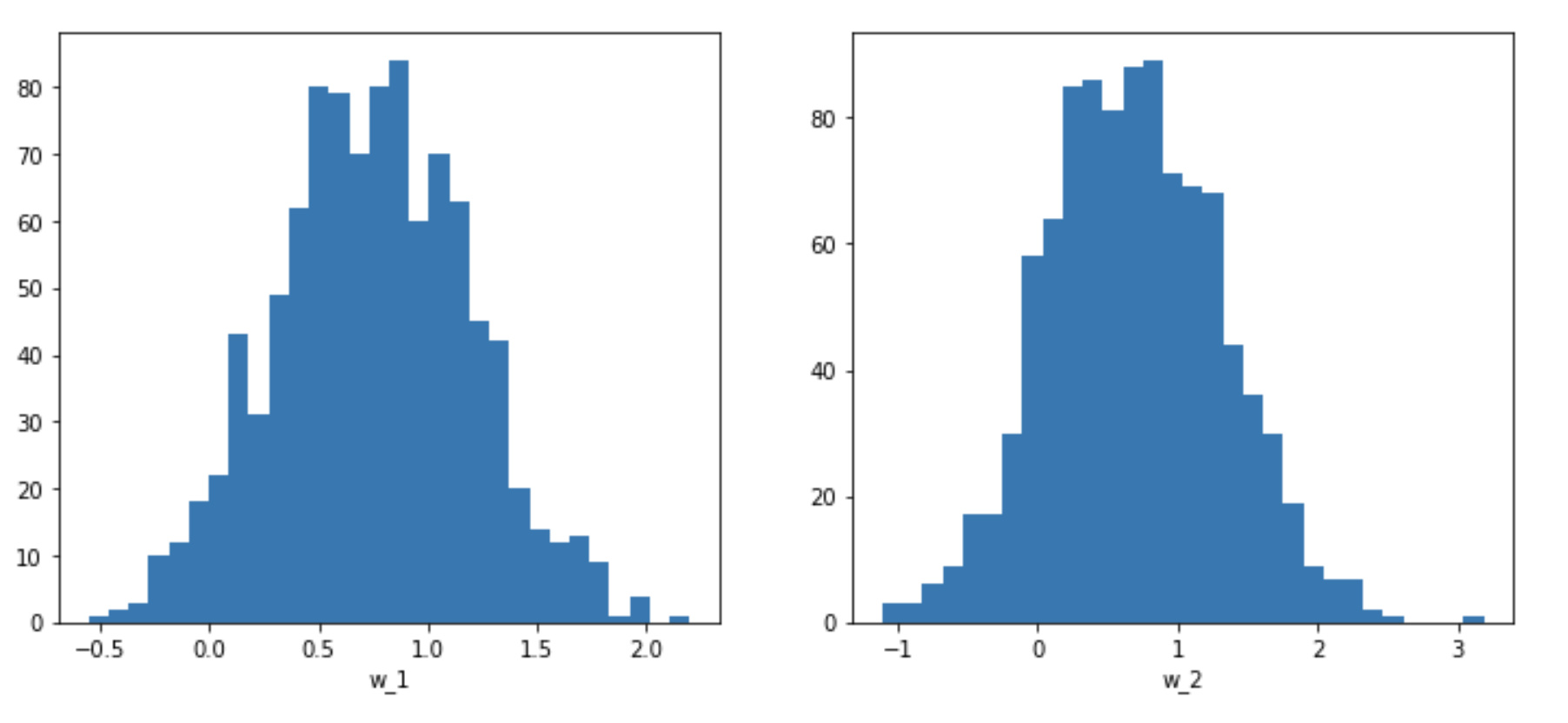
The posterior of sigma seems to be values closer to 1 than 0.1 as used in the example.
So my questions are:
- Have I specified the model wrong?
- Anything else that is wrong here?