I’m interested in finding the likelihood of my model as a distribution over parameters.
However, pm.traceplot seems to plot the posterior distribution instead of the likelihood distribution.
I use a Dirichlet prior, instead of an uniform prior, to constraint the parameters to a simplex.
Can I plot the distribution of likelihood for all parameter values that pymc has sampled?
Can I get the trajectory of likelihood from the trace?
It’s kind of a strange question. Are you sure that you want to plot the likelihood instead of the model’s logp?
The model defines a probabilistic graphical model. The first question you should answer is: what is the likelihood in that graph? It should be proportional to the marginal logp of the observed RVs. What is the likelihood if you have more than one observed RV? And if one observed depends on the other? And if there are potentials?
Let’s just assume that your model has a single observed RV and no potentials. The trace holds parameters that are distributed consistently with the posterior probability distribution. To get samples that follow the posterior we use the model’s logp. It’s easy to compute the model’s logp for all points in the trace like this:
import numpy as np
import pymc3 as pm
# Define a toy test model and get a trace
with pm.Model() as model:
mu = pm.Normal('mu', 0, 1)
sigma = pm.HalfNormal('sigma', 1)
obs = pm.Normal('obs', mu=mu, sigma=sigma, observed=np.random.normal(loc=5, scale=3, size=100))
trace = pm.sample()
logp = model.logp
model_logps = np.array([logp(point) for point in trace.points()])
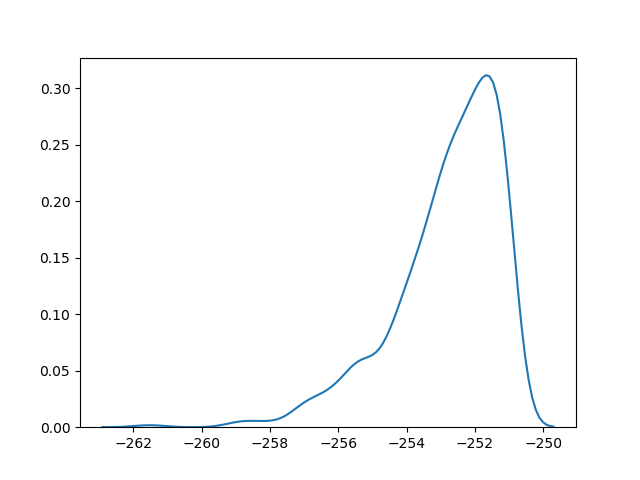
You can then plot the “distribution” of the model logp's values across all points in the trace like this:
import seaborn as sns
sns.kdeplot(model_logps)
which gives you roughly something like this:
You could compute the observed’s logp, which should be analogous to the likelihood of the observations:
obs_logp = obs.logp
likelihood = np.array([obs_logp(point) for point in trace.points()])
sns.kdeplot(likelihood)
Sorry. Maybe I didn’t describe clearly in my original post.
My goal is to find the highly likely values for the parameters \theta of the model.
I think that means I want:
Plot of the log-likelihood (logp) as a function of the parameters \theta. The plot will not display anything for the values that the sampler hasn’t visited.
Not a histogram of log-likelihood values.
Not a histogram of the values of the parameters. That is the posterior distribution.
The traceplot is frequency vs value. I guess that describes the posterior distribution instead of likelihood of the parameters.
I don’t know if I should believe my prior is “weakly-informative”.
I am using Dirichlet instead of uniform prior. I saw that Dirichlet with \alpha = \vec{1} look like a triangle with uniform density. Maybe in that case, the prior is indeed weakly-informative?
Wikipedia’s page of Bernstein-von Mises theorem says:
“that the posterior distribution for unknown quantities in any problem is effectively asymptotically independent of the prior distribution (assuming it obeys Cromwell’s rule) as the data sample grows large”
How large is large enough for that to work? What are the assumptions?
Ok, so if that is your goal, then you can achieve it calling the logp (for the model or the observed RV depending on what you want). You just need to make sure you pass dictionaries of RV names as keys and the corresponding value with the shape of the RV. You’ll also have to include the autotransformed RV’s into the dictionary like this:
from matplotlib.colors import SymLogNorm
mu = np.linspace(0, 10, 100)
sigma = np.linspace(0.5, 8, 80)
mus, sigmas = np.meshgrid(mu, sigma)
# As we will evaluate the logp many times, it's faster to assign the callable to a name
# This happens, because model.logp (or RV.logp) compile a theano function and return it
logp = model.logp
def likelihood(mu, sigma):
# We add the autotransformed sigma_log__ entry to the point
return logp({'mu': mu, 'sigma': sigma, 'sigma_log__': np.log(sigma)})
# Just to save us the trouble of iterating through the grid of values
f = np.vectorize(likelihood)
liks = f(mus, sigmas)
# Get the maximum "lik"
sigma_ix, mu_ix = np.unravel_index(np.argmax(liks), liks.shape)
plt.pcolor(mu, sigma, liks, norm=SymLogNorm(0.5))
plt.xlabel(r'$\mu$')
plt.ylabel(r'$\sigma$')
plt.colorbar()
plt.plot(mu[mu_ix], sigma[sigma_ix], 'or')