Hi evertone from the comunity.
I am a beginner on data analysis in general and I have this project to do and I hope someone could give me some advice.
The project consists of modelling counting data with a Poisson regression model and make point estimate the paramaters of the model using Metropolis-Hastings algorithm using pymc3 library.
The dataset that I have to use is a very simple one. It’s about observations of Insurance Motor Third Party Claims (both frequenct and severity). I’ll link the full description of the dataset below.
https://search.r-project.org/CRAN/refmans/GLMsData/html/motorins.html
There are two issues that I am dealing with:
-
Do I have to do some preprocessing step before running the algorithm? If so, how do I do it?
-
I built a model following the Poisson regression model in the example section, but still the the algorithm is too slow. How I can improve performance?
Here is the code I used until now:
import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc3 as pm
import seaborn as sns
import theano
import theano.tensor as tt
import xarray as xr
from formulae import design_matrices
print(f"Running on PyMC3 v{pm.__version__}")
print(f"Running on Arviz v{az.__version__}")
df = pd.read_csv('SwedishMotorInsurance.csv')
df.head()
df['Rate']=df['Claims']/df['Insured']
fml = "linear ~ Kilometres + Zone + Bonus + Make"
df_1=df[['linear','Kilometres','Zone','Bonus','Make']]
dm = design_matrices(fml, df_1, na_action="error")
mx_ex = dm.common.as_dataframe()
mx_en = dm.response.as_dataframe()
with pm.Model() as model:
# define priors, weakly informative Normal
b0 = pm.Normal("Intercept", mu=0, sigma=10)
b1 = pm.Normal("Kilometres", mu=0, sigma=10)
b2 = pm.Normal("Zone", mu=0, sigma=10)
b3 = pm.Normal("Bonus", mu=0, sigma=10)
b4 = pm.Normal("Make", mu=0, sigma=10)
# define linear model and exp link function
theta = (
b0
+ b1 * mx_ex["Kilometres"].values
+ b2 * mx_ex["Zone"].values
+ b3 * mx_ex["Bonus"].values
+ b4 * mx_ex["Make"].values
)
## Define Poisson likelihood
y = pm.Poisson("y", mu=tt.exp(theta), observed=mx_en["linear"].values)
with model:
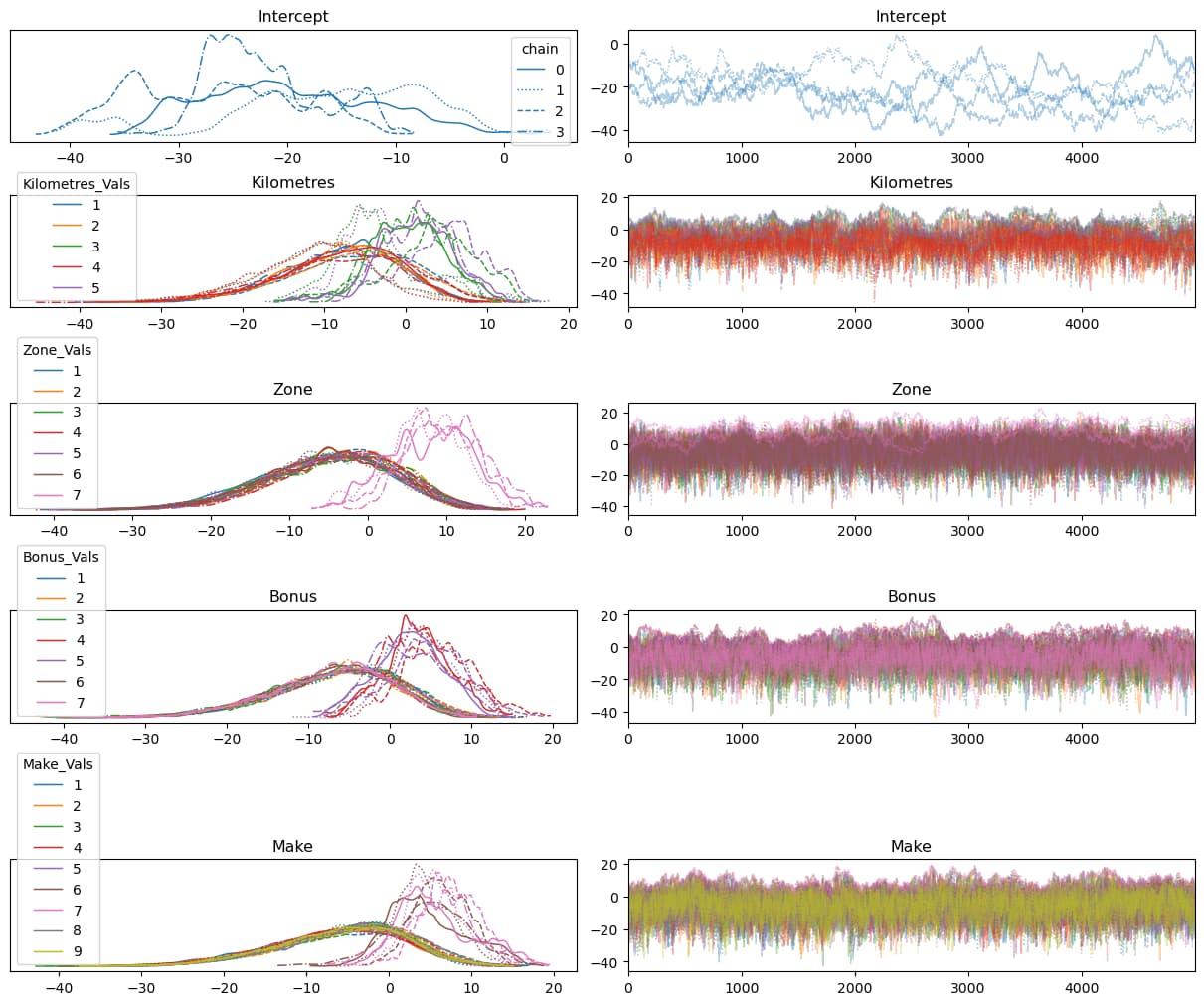
trace = pm.sample(draws=5000, tune=500, cores=4, random_seed=45, step=pm.Metropolis())
pm.summary(trace)
How would you modify it?
Here is the dataset file.
SwedishMotorInsurance.csv (49.6 KB)
Hope this would be useful for other beginners like me.