Hi everyone. I’m currently trying to model some EEG data via a Gaussian random walk (GRW). In particular, I have some difference waves from event-related potentials (ERP) epochs in a 32 X 2 X 282 matrix, where electrodes = 32, groups = 2, and samples = 282 (i.e. 282 timepoints each associated with an amplitude value in microvolts). The model looks as follows:
with pm.Model() as mod:
sd = pm.Exponential.dist(0.5, shape=E) ##E = 32 electrodes
chol, corr, std = pm.LKJCholeskyCov("chol", n=E, eta=2.0, sd_dist=sd, compute_corr=True)
cov = pm.Deterministic("cov", chol.dot(chol.T))
g_raw = GRW("g_raw", shape=(S,E,G), sigma=0.5) ##S = 282 samples, G = 2 groups
g = pm.Deterministic('g', tt.dot(cov, g_raw.T))
a = pm.Normal('a', mu=0, sigma=0.5)
m = pm.Deterministic('m', a + g)
e = pm.Exponential('e', 0.05)+1
y = pm.Normal("y", mu=m, sigma=e, observed=amps, shape=amps.shape)
I have sampled this model using NUTS (2000, tune=2000, chains=4, init=‘advi’, target_accept=0.95) and the “g” parameter completely fails to converge, with R_hats over 1.4. However, the ERP signals are approximated very well.
Similarly, I have tried using ADVI (20000, callbacks=[tracker, checks], where tracker tracks mean and std, and checks = CheckParametersConvergence(diff=‘absolute’)) and it does not converge, but it approximates the signal very well. Here’s the ADVI approximation at one electrode (Pz):

And here are the results of the ADVI tracker:

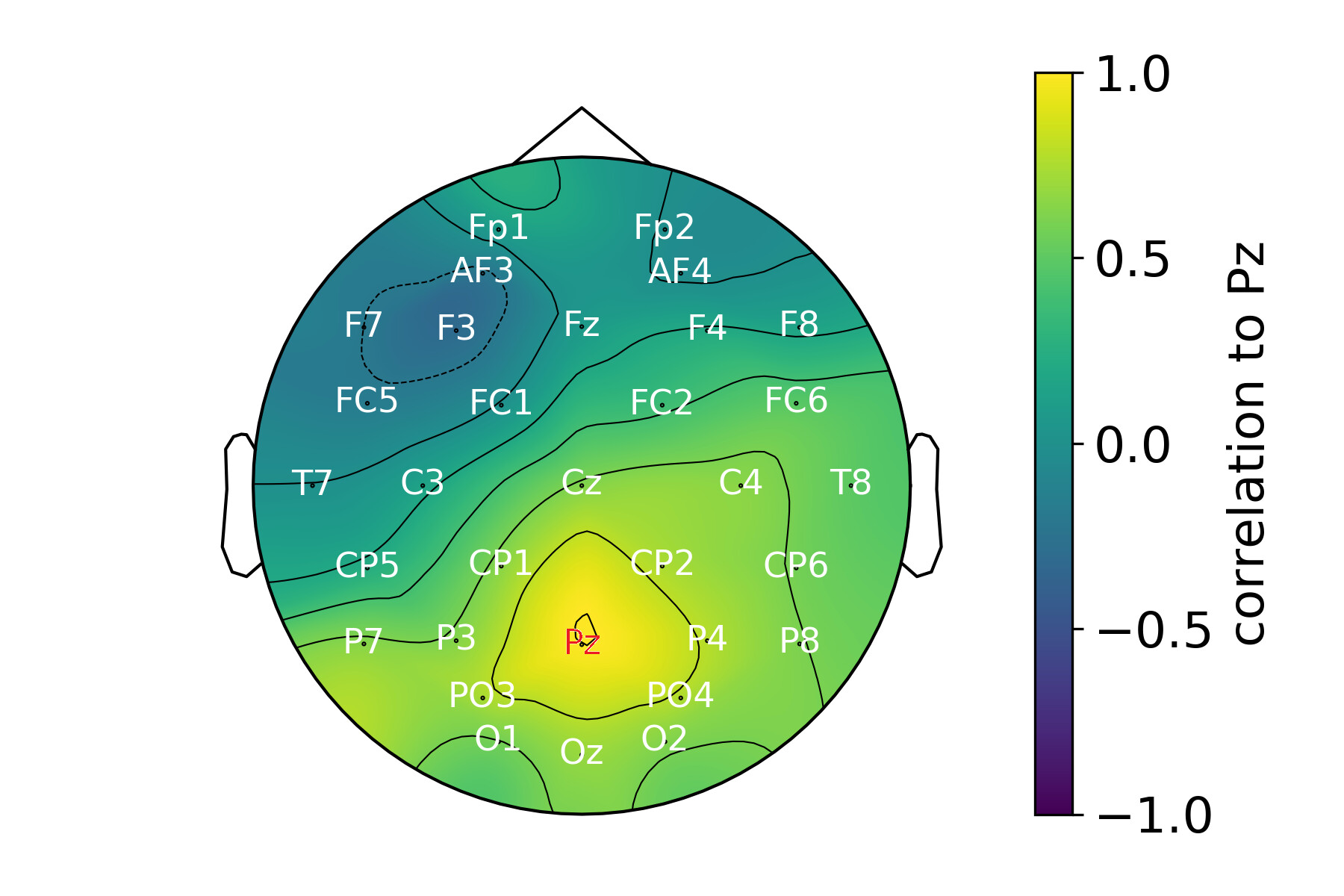
Curiously, the correlations from the LKJ prior are also sensible. In neuroscience EEG research the P300 ERP is commonly observed in an electrode cluster surrounding posterior electrodes such as Pz. This is what I get from few electrodes around Pz (makes sense):
| P3 | P4 | Pz | PO3 | PO4 | |
|---|---|---|---|---|---|
| P3 | 1.00 | 0.42 | 0.50 | 0.53 | 0.46 |
| P4 | 0.42 | 1.00 | 0.59 | 0.53 | 0.56 |
| Pz | 0.50 | 0.59 | 1.00 | 0.59 | 0.58 |
| PO3 | 0.53 | 0.53 | 0.59 | 1.00 | 0.55 |
| PO4 | 0.46 | 0.56 | 0.58 | 0.55 | 1.00 |
My impression is that my model is fundamentally flawed, but I cannot figure out where the problem is. Maybe a GRW is not appropriate for this type of data (though ERP waves are technically time series of amplitude). Maybe the LKJ prior is not appropriate (I don’t know of any possible replacement). Mathematically I’m a bit at a loss, as I’m not able to say what may be producing such a problematic posterior (in terms of sampling at least), though a posterior that gives coherent results. When I replace the LKJ prior by diagonal matrix of ones (tt.eye(E)), the model converges well (the drawback is that all the information about correlations between electrodes is lost/unaccounted).
Any help or comment will be sincerely appreciated. Many thanks in advance.