I am struggling to wrap my head around the discrepancy I am observing in the estimates provided by statsmodels and a model I wrote in PyMC3 of an AR(1) process. Given this toy simulated data
n = 300
x = np.random.normal(31, 1, n)
x_ar = np.array([x[i] * 1 if i == 0 else x[i] + (x[i-1] * .6) for i in range(n)])
y = np.random.normal(30, 1, n)
y_ar = np.array([y[i] * 1 if i == 0 else y[i] + (y[i-1] * .6) for i in range(n)])
delta = x_ar - y_ar
I would like to reliably estimate the expected value of the difference of the two AR processes delta (which I know is 1), calculating the empirical median gives as expected a biased estimate
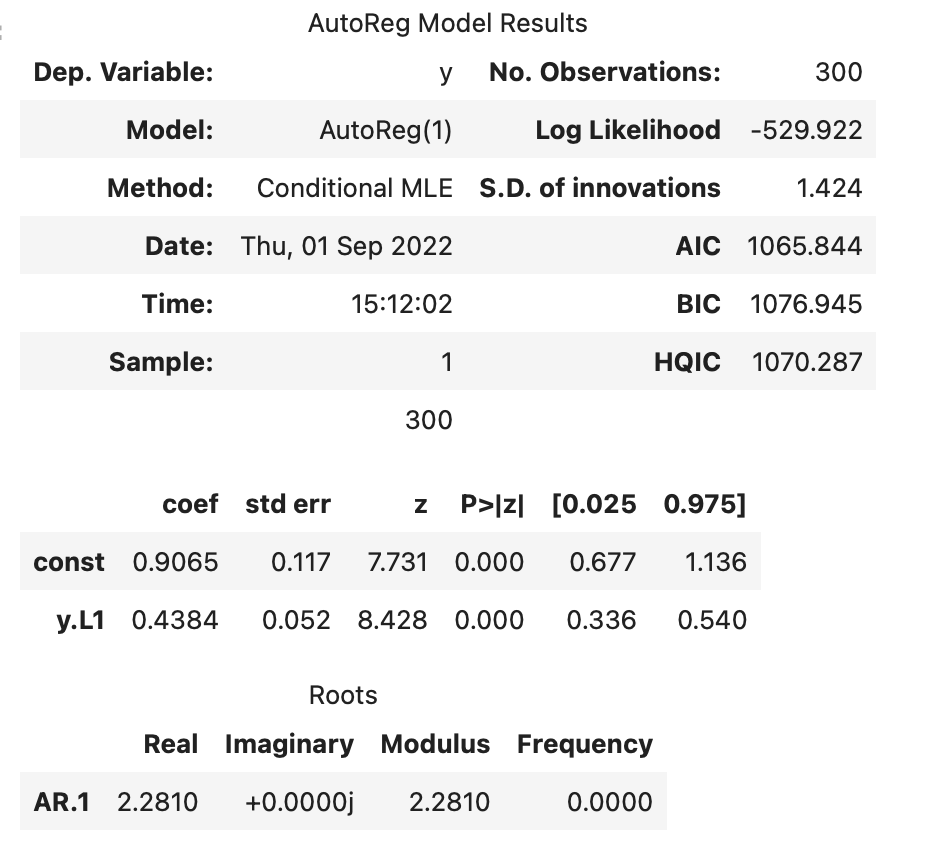
While statsmodels AR seems to retrieve the right values for all the parameters with reasonable success
This has been solved by using the implementation of AR in PyMC V4 and specifying constant=True and having rho including the value for the constant.
I assume (please correct me if I am wrong) the model specification above is fundamentally different and the constant is not included in the AR process.
The PyMC V4 AR distribution indeed includes the constant as the 0th rho. Here is some relevant code from the AR distribution that shows how the constant is handled:
You can see if the first branch of the if statement that when there is a constant term, the last “reversed_rho” (or the first regular rho) is used as the constant value.
There is a slight difference between the PyMC implementation and the Statsmodels, because Statsmodels uses the “Regression with ARIMA errors” formulation, as explained here. Rob Hyndman writes about the difference here. PyMC’s implementation would be an example of what Hyndman calls the ARMAX model, where \beta is the constant coefficient and x is a vector of ones, and \theta(B) = 0. So you have to do a bit of algebra to convert from one to the other.
In general it’s advisable to difference away the constant term when working with ARIMA class models, if you can. For one thing it avoids these headaches. Just centering and scaling the data will also let you omit the constant term.