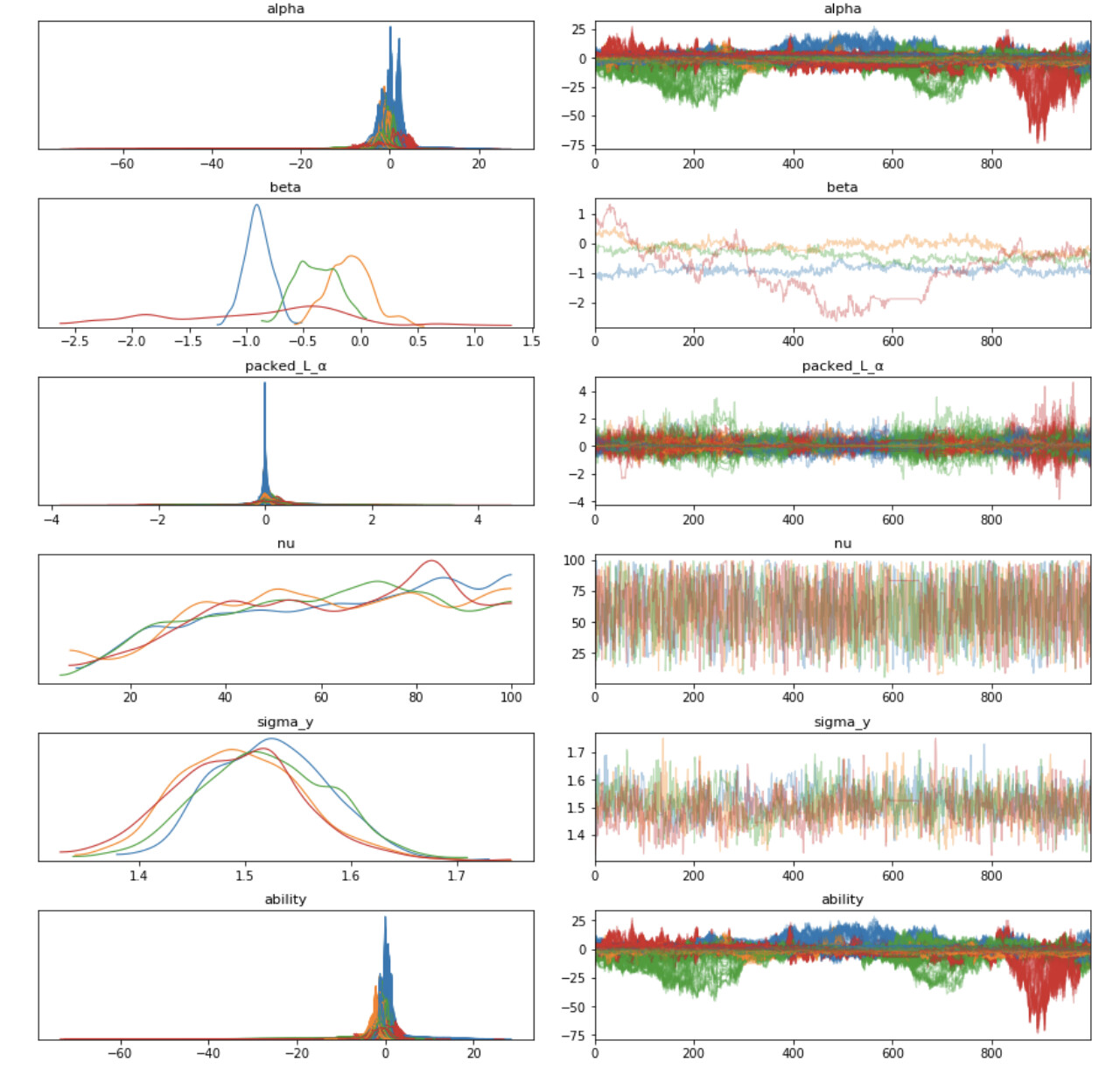
The model predicts match scores in Serie A (Italian Football) with a latent variable, ability, which is a teams tendency to outscore another team. My personal goal is to be able to infer teams ability and how it changed over time.
The model had 3 divergences and the traceplots look terrible, but a lot of the inference make sense - for instance, AC Milan’s tendency to outscore other teams had a huge leap that matched their performance change.
Milan’s isn’t the only one that makes sense - inference for a lot of these teams look credible and match how they’ve been performing.
My question is - how do I take this mis-specified model that might be on to something and make it more properly specified? Example notebook attached (change the extension to .ipynb)
Not sure how helpful this is but I have had issues with trying to infer the degrees of freedom of a student t as part of models in the past. I suspect it can be weakly identified. My suggestion would be to try to fix nu to a value that you think is reasonable and see if that helps things!
Really good suggestion, makes a lot of sense thank you! I ended up getting a better fit by changing to a GRW, as well as switching from a multivariate to just a no pooling Gaussian random walk and adding an AR1 term. Here’s the model
I can’t figure out why having both a RW and an AR1 process lead to the best model. Is that weird theoretically?
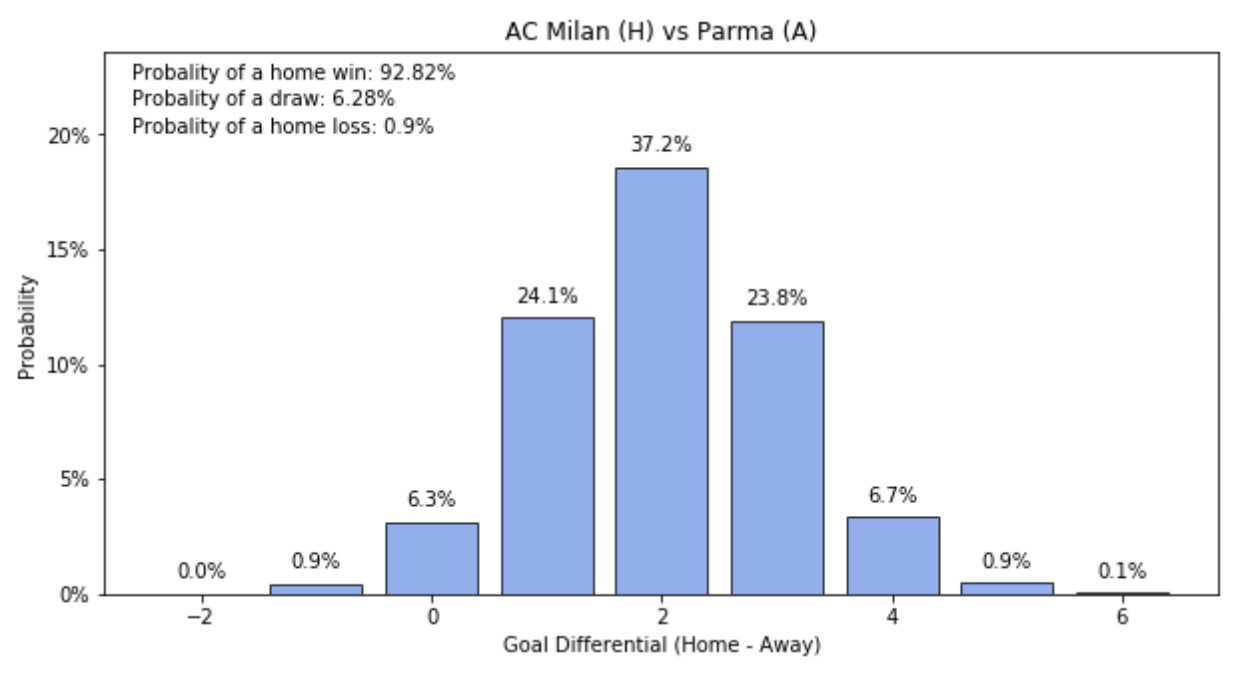
Is there a clever way I can add a prior that limits extreme match results and add more weight to predictions around 0? Example of why my current model is problematic below
Indeed having two time series is a bit strange. I think you are over fitting to the data. I only quickly read the code but it seems like ‘t’ data is essentially per a match for each team. The AR1() process has a high standard deviation of innovations so it will essentially fit to each match result, and thus have no predictive power. You could either reduce the sigma or have the t variable apply for a few matches at a time.
As an aside you might be interested to look into pd.factorize(), this could be used rather than your custom codify() function.