Exactly so, and I guess I should have been more precise with my language. Certainly some more elaborate models (in economics at least, where I have an iota of a clue) put interpretable meaning to the random shocks. It’s just unusual to talk about the unobserved technology shock to production in 1992, since the usual object that is discussed is the distribution of these shocks over the whole time series. But, now that you mention it, people do do shock decomposition, so I guess we get that decomposition “for free” by estimating T x k epsilons.
One thing I didn’t understand first looking at the output graphs was that the PyMC state estimates are much closer to the smoothed Kalman states than to the filtered ones. In principal, this should not be the case, since there’s no integration of future information into the PyMC model. Is this resemblance just superficial, caused by the fact that the innovation series is embedded in the filtered results?
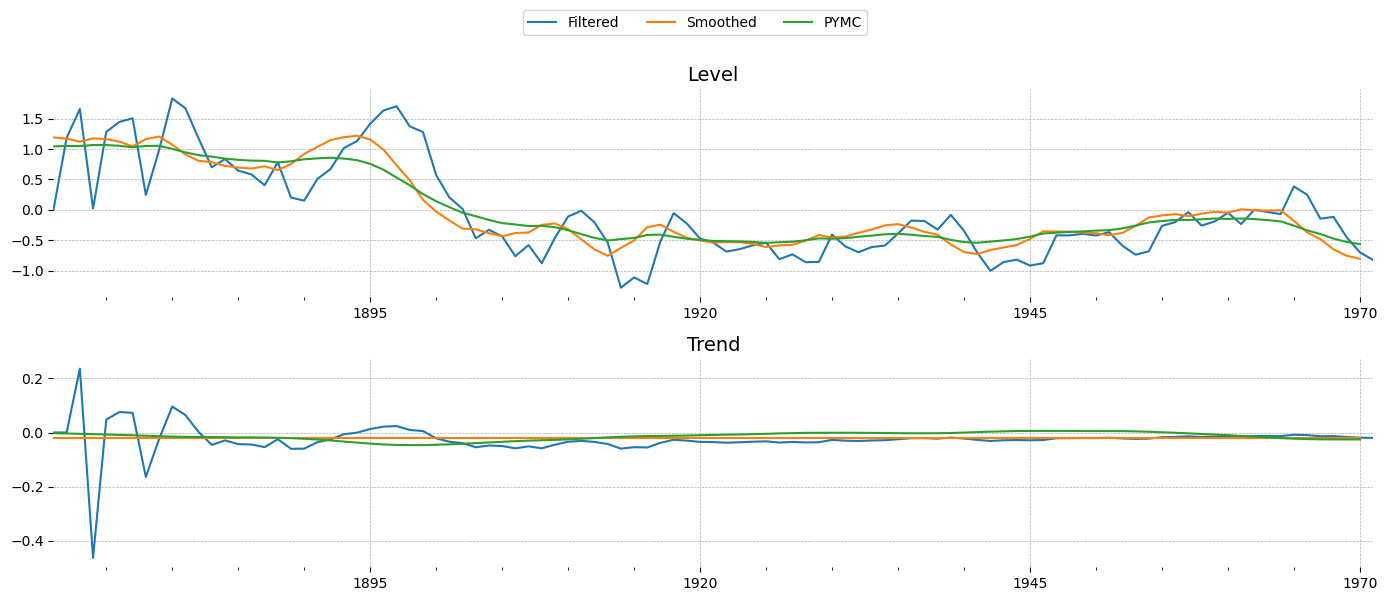
Also, thank you for linking your repository, it looks extremely relevant to the types of problems I’m working on. I’ll have a look at what you’ve done and try to learn from it, or give up and try to use it directly!