I am new to PyMC and have run into an odd issue in which the more data points I get, the worse of an answer I get.
I have been following this example of modeling a Gaussian distribution with an unknown standard deviation (see especially equations 1 and 6). I create my sample by drawing N~10 data points from a normal distribution with standard deviation 2.5 with numpy.random.normal().
To estimate the standard deviation, I use a Poisson likelihood with mean equal to the value of a normal distribution with a given standard deviation.
true_sigma = 2.5
num = 50 # Length of dataset
vs = np.random.normal(0, true_sigma, num) # Create normal distribution with standard deviation of 2.5
counts = np.ones_like(vs)
with Model() as model:
# Define prior
sigma = Uniform('sigma', lower=0, upper=20)
# Define likelihood
likelihood = Poisson('y', 1/sigma * np.exp((-(vs)**2)/(2 * sigma**2)), observed=counts)
idata = sample(10000, tune=5000)
When I run PyMC on this, the posterior for the standard deviation is very close to the true value (2.5) used to create the data.
When I increase the number of data points (N=500, 5000), the posteriors become increasingly offset from the true value until eventually the correct number is completely ruled out.
These are the resulting posteriors for different lengths of data.:
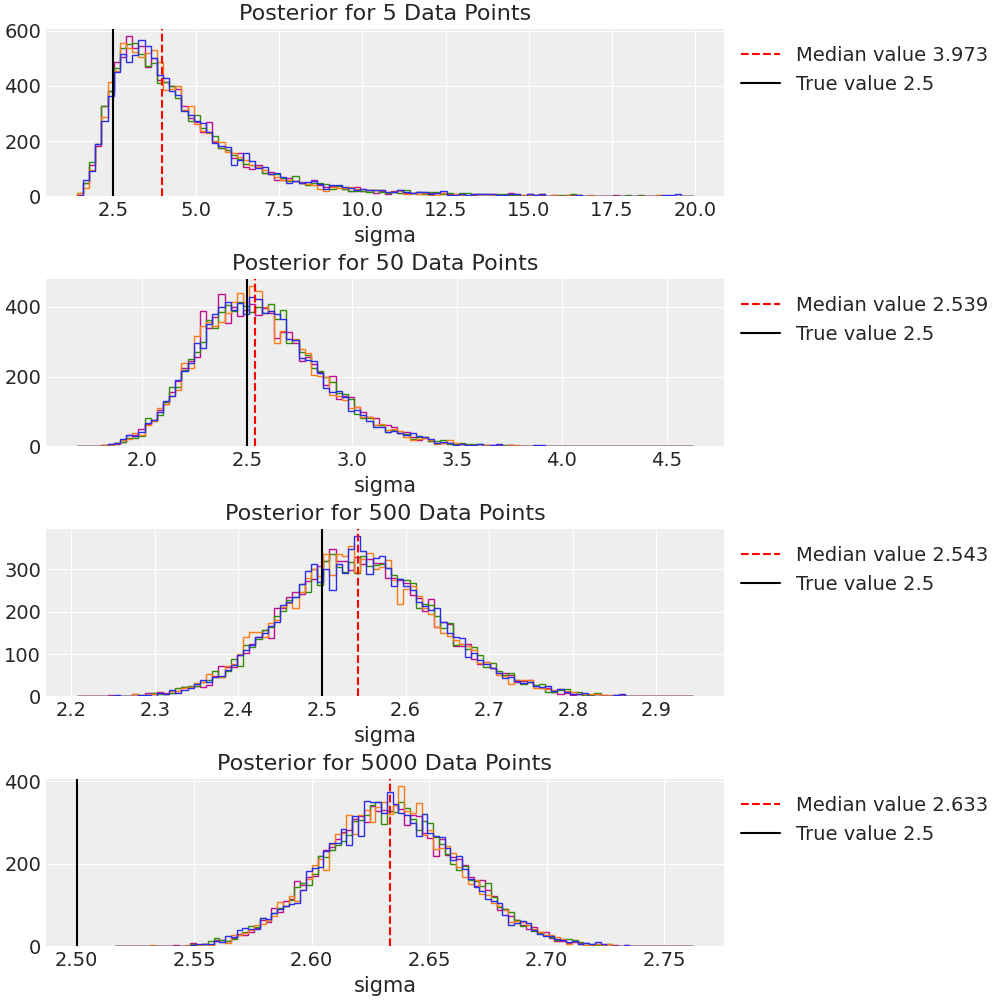
What is happening here?