Hi, could someone explain what is exactly the average loss that appears in the advacement bar during the initialisation (with ADVI)? What behaviour should we expect from that number?
Average Loss = 2.1759e+07: 100%|██████████| 10000/10000 [02:11<00:00, 89.31it/s]
I’m new to variational inference, and I didn’t find any documenation about that.
Hi @mcavallaro, in ADVI the loss is the negative of evidence lower bound (ELBO) within some window. You can not compare it across model, as it is non-normalized. What people usually do is plot it so you can check whether your model converge or not (converge to a local minimum at least). eg: http://docs.pymc.io/notebooks/variational_api_quickstart.html#Minibatches
@twiecki Thanks! Good to know that there is a canonical way to debug theano functions! In my case the loglikelihoods are finite, still, it’s strange that the Average Loss in my post above is reported to be infinite first and then equal to 1,162.4.
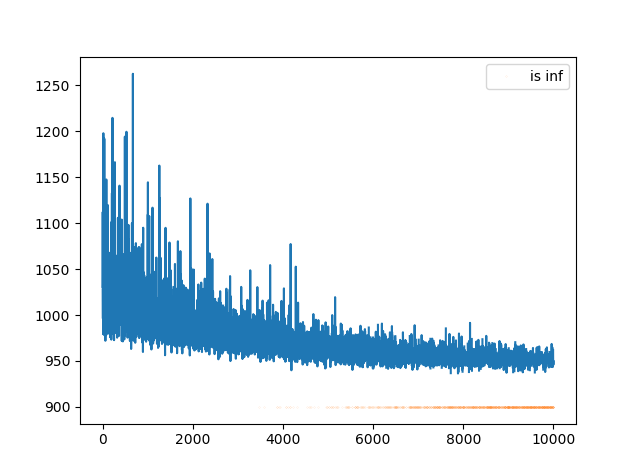
I obtain that the trace for the ELBO, f.hist contains lots of inf, (just inspecting np.where(f.hist== np.inf) , see the orange points in the pic below), but no warnings or errors…
Conversely,
with model: s = pm.sample()
eventually raises the bad initialisation / model mispecification error.
Also, doing:
for RV in model.basic_RVs:
print(RV.name, RV.logp(model.test_point))
only finite values are printed, no inf or nan.
It is possible to plot a trajectory for the stochastic node during the ADVI step (similarly to what we do with plot(f.hist) )?
I think this is an indication of some hidden problem in your model (e.g., some parameter goes negative and then feed to something needs a positive input).
I was experiencing a similar average loss inf problem in some of my models since updating to 3.2 and was able to recreate it in an extremely simple regression model (the models didn’t produce this in earlier versions of pymc3). It appears as though the model converges but then produces inf values for average loss. Code here: https://github.com/schluedj/test_examples/blob/master/Simple_Regression_infs.ipynb
Any ideas what this might be in such a simple model?
Hi David,
During the approximation, some parameters might went outside of the supporting range which cause the -inf. Looking at the loss history the fitting should be fine thought. You should track the parameters of the approximation (see instruction here), and pin down what is causing the -inf.
Thanks! Yeah tracked the parameters for the mean-field approximation and all looked okay. However, it’s the full-rank that’s giving me problems. For the full rank, we’ve got the mean of the approximation and the lower triangular of the cholesky decomp of the covariance matrix of the variational distro (which is what I’m assuming L_tril stands for). How do I go about tracking the covariance matrix?
Thanks for looking into this. I actually didn’t have a problem fitting mcmc on a smaller dataset. My “model_vi” model has a mini-batch setup; perhaps you’re getting the ValueError because you’re trying to run sample in a model where the data is mini-batched?
Like I said before, for me this is something that has popped up in more complicated models that worked in previous versions of pymc3. One “sort of” fix that I found with some of these models was to change the obj_optimizer and learning rate (through a lot of trial and error). However, I did not have universal success with doing this.
Hi David,
It would be great if you can open a new post with a bit more details on the problems you are having. My hunch is that (at least in this example) some denominators become too small, while this doesn’t affect the final estimation (as the model converges to a local minimal), it is not ideal and could indicate bias somewhere.