Hello PyMC3 community, it would be really great to get your evaluation of my PyMC3 formulation of the simple hiearchical model. Somehow even on the synthetic data, the results are weird and there are two possible options for it: either I do something wrong in the PyMC modeling or the problem by itself is not well formulated for an approach chosen.
Formulation of the model:
Participant j \in [1 \dots N] completes the task i \in [1 \dots T] by choosing one of the two provided options (ways of completing the task) a_{ji} and b_{ji}. Each option a_{ji} and b_{ji} can characterized by two components:
We assume that components a^{\circ}_{ji} and a^{\bullet}_{ji} are not identical in the cost percieved by participant. We model the difference in cost of options:
The ultimate goal of the analysis is to estimate \beta_j — participant-specific inflation coefficient of component \circ as compared to component \bullet of costs associated with completing the tasks.
We model the choices in a probabilistic way. Probability of choosing option a_{ji} at choice i by participant j:
Where y_{ij} is indicator variable of whether option a_{ji} was chosen, \tau_j is a temperature parameter individual parameter for each participant, reflecting the sensitivity of participant’s decisions to the difference in the option’s costs.
In this model we assume that no learning is involved, the parameters are static during the experiment and that the decisions made by participant are independent one from another. Thus, likelihood of observing the decisions y_{j} = \{y_{ji}, \dots, y_{jT}\}:
The hiearchical model can be expressed by diagram:

The PyMC3 model formulation looks as follows:
def pymc_hier_model(choices, a_components, b_components, participants, cauchy_param=5.):
""" Build the PyMC3 hiearchical model of choices.
Args:
choices (np.array(N*T)): Array of indicators of whether option A was chosen by participant.
a_components (np.array(N*T, 2)): Array of components characterizing option A.
First column is circle component, second column is bullet component.
b_components (np.array(N*T, 2)): Array of components characterizing option B.
Analogous to previous param.
participants: (np.array(N*T)): Array of identifiers of participant, who made a particular choice.
Each element is in [0 ... N-1].
cauchy_param (float): Parameter of hyperprior Half-Cauchy distribution.
Returns:
pm.Model: Hiearchical model of the choices.
"""
participants_n = participants.max() + 1
with pm.Model() as model:
# a_beta, b_beta, a_tau, b_tau
hyperparams = pm.HalfCauchy('hyperparams', cauchy_param, shape=4)
beta = pm.Gamma('beta', hyperparams[0], hyperparams[1], shape=participants_n)
tau = pm.Gamma('tau', hyperparams[2], hyperparams[3], shape=participants_n)
delta_c = beta[participants] * (a_components[:, 0] - b_components[:, 0]) \
+ (a_components[:, 1] - b_components[:, 1])
p_dec = pm.Deterministic('p_dec', pm.invlogit(-delta_c / tau[participants]))
decisions = pm.Bernoulli('decisions', p_dec, observed=choices)
return model
The questions would be:
- Does the formulation look OK?
- If yes, why could that be that I get on the data generated with assumed data-generating process estimates of parameters (means), which no way look like accurate:
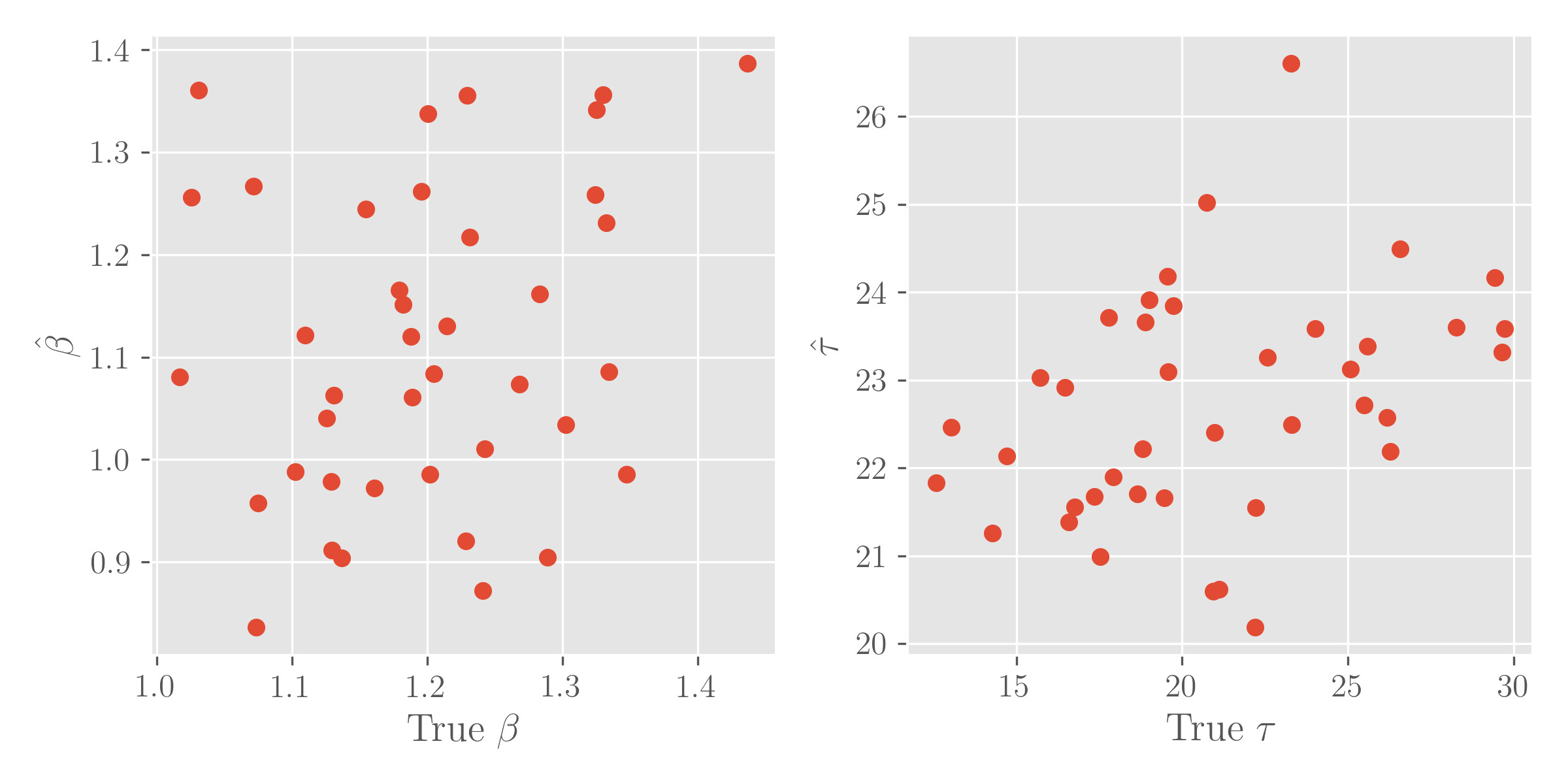
Thank you in advance!









