Hi folks,
I can’t decide whether my model is wrong or I’ve misunderstood something. I’m using pymc v4 for a Gaussian Process (the marginal likelihood implementation - model explanation is at the end). My goal is to get estimates for the covariance hyperparameters.
Context
My posterior predictive check on the outcome is as follows:

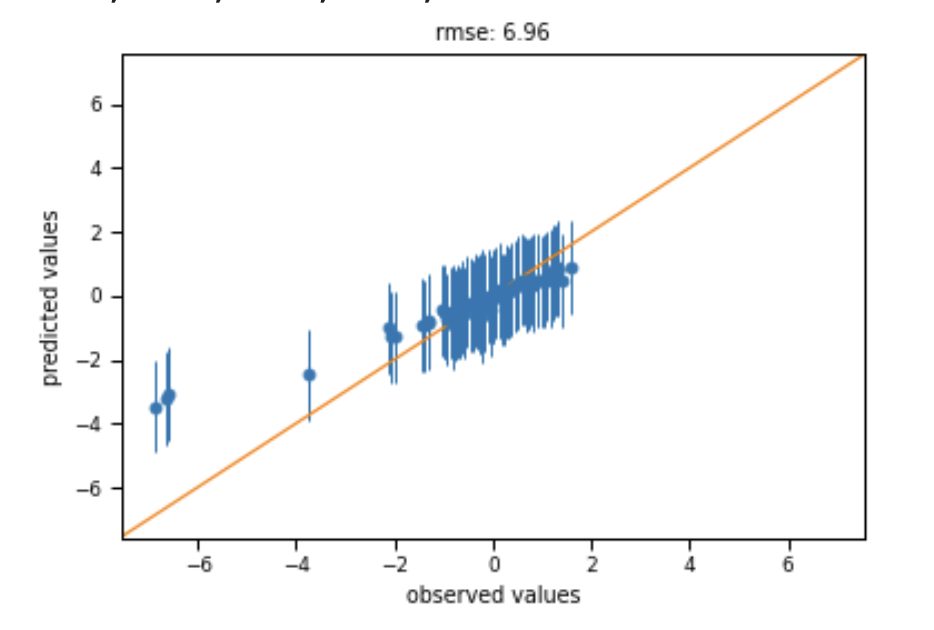
However, when I try and plot the mean predicted vs observed values I get a flat prediction:

I’ve tried fitting the GP using pm.find_MAP but this is highly dependent on the initial conditions (the start parameter) but it does give OK-ish predictions:
Question 1: is my calculation of the mean and standard deviation of p(\hat{y}_i|y_i) (y_mean/std above) correct? (FYI: I wouldn’t normally use the standard deviation - it’s just a quick and dirty way of getting errors for the purposes of this post.)
Question 2:
Asking for the other variables in the PPC function gives me drastically different values for the PPC of the outcome:

What is going on here? Shouldn’t PPC be independent of what variables you ask to draw from it?
Model explanation
with model:
gp = pm.gp.Marginal(cov_func=cov)
y_ = gp.marginal_likelihood('y_', X=X, y=y, noise=sigma_n)
trace = pm.sample(draws=1000, tune=1000, chains=2, cores=2, target_accept=0.90)
cov is a product of 5 exponential kernels over the columns of X and a general scale term:
eta = eta_prior('eta')
cov = eta**2
for i in range(X.shape[1]):
var_lab = 'l_'+X_labels[i]
cov = cov*pm.gp.cov.Exponential(X.shape[1], ls=l_prior(var_lab), active_dims=[i])
The priors are all weakly informative (prior predictive checks show that the outcome 90% of the time lies within the observed range). eta, sigma_n ~ HalfCauchy(1); all other parameters ~ Gamma(1, 0.5). The trace plots and summary statistics all show good convergence. Running it for 10’000 draws doesn’t materially change anything.
Thanks in advance!