I have been playing around with PyMC for roughly a week now. I have also started listening to @AlexAndorra’s Learn Bayesian Statistics podcast and I must say that intaking all these discussion on Bayesian statistics together with his enthusiasm for it have made me really want to learn and master this art.
I am not a statistician or mathematician so this knowledge comes slowly to me. I am using Python for less than a couple of years and I used sklearn a few times whenever I had a bit of free time to study the Elements of Statistical Learning book.
To the question:
I am currently working on a project to classify a commandline as malicious or not. For this reason, it makes sense to look into Bayesian statistics since: i) prior knowledge can be very helpful and, ii) it helps me better understand what the model is doing.
I started playing with a logistic regression model where I set all priors ~ N(0,1); but given that my features are all discrete values (0 if that word or bigram doesn’t appear in the sample; N otherwise, with N being the count of how many times it appeared) I figured it might be better to use discrete distributions for my priors. The classification was quite OK [4 misclassified], but nothing different from some logistic regression in sklearn (obviously, since I haven’t really used the advantage of Bayesian statistics such as prior knowledge)
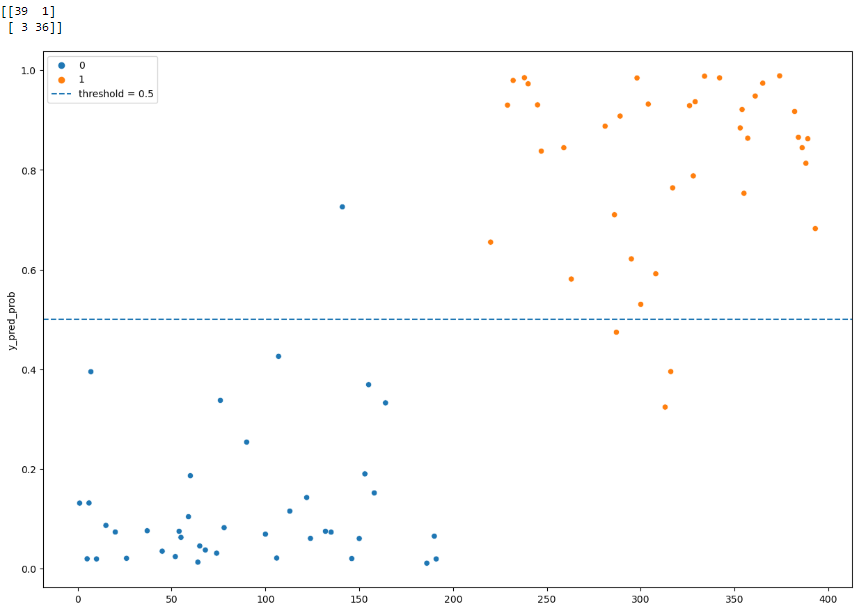
orange = malicious, blue = not-malicious, threshold of my classifier
I tried using pm.Bernoulli for my priors, where I could set p to close to 0 for features that are usually benign and p close to 1 for features that are usually malicious. To start, I set all features to p=0.5; but the classification wasn’t good at all. All features had a probability > 0.5 and there was no clear distinction between malicious/benign data.
It seems that I am clearly misusing the pm.Bernoulli distribution in this scenario. Could someone point me in the correct direction for this application that I am looking into? I have read the Prior Choice Recommendations · stan-dev/stan Wiki (github.com) but it seems that most of that post is focused on continuous distributions.
Hey, nice to see you here, and thanks for you kind feedback about the pod!
From what you’re saying, I’m not sure you need discrete priors – which would be way better, as dealing with discrete parameters is still way harder (that’s also why the Stan page you linked to focuses on continuous distributions).
It would be helpful if you shared the model here.
In any case, I encourage you to read the chapter about logistic regression in @aloctavodia’s book – seems like it’s really close to what you’re doing
@AlexAndorra thanks for the suggestions. I bought the book and I’ll take a look at the chapter [and, with time, the whole book]
@cluhmann, I’m note sure I understand how to use binomial regression for this application, and I can’t really think on how to implement the n trials idea in my specific problem.
In my specific case, my target variable is either 0 or 1 (benign or malicious commandline), in Binomial regression their target variable can be any number between 0-n
The model I did so far below, usually with mu_beta = 0, sigma = 1 and constant = 0 (same as in the binomial regression notebook). I have little samples and almost 2k predictors, they can be ranked into usually benign to usually malicious with help from experts.
It’s funny that it seems to classify better with mu_beta = -1 and sigma = 1 but I don’t know why.
In any case, my question was more related on a different distribution than pm.Normal for my betas. Or how should I think about my betas to find a more suitable distribution.
with pm.Model() as model:
X = pm.MutableData('X', X_train)
y = pm.MutableData('y', y_train)
beta = pm.Normal('beta', mu=mu_beta, sigma=sigma_beta, shape=len(X_train.columns))
if constant:
constant = pm.Normal('constant', mu=mu_constant, sigma=sigma_constant)
else:
constant = 0
p = pm.Deterministic('p', pm.math.sigmoid(constant+X@beta))
observed = pm.Bernoulli('obs', p, observed=y)
idata = pm.sample(chains = chains)
idata_prior = pm.sample_prior_predictive(samples=50)
with model:
pm.set_data({'X':X_test, 'y':np.zeros_like(y_test)})
y_pred = pm.sample_posterior_predictive(idata)
I don’t see any obvious problems in this model, which made me think I’m not sure I understand the issue you’re having: does the model have problem sampling?
I’m note sure I understand how to use binomial regression for this application, and I can’t really think on how to implement the n trials idea in my specific problem
The Bernoulli is just a special case of the Binomial, where n_trials = 1.
I have little samples and almost 2k predictors
What do you mean by that? Your X matrix has 2k columns?
The model I did so far below, usually with mu_beta = 0, sigma = 1 and constant = 0
Setting constant = 0 means your model doesn’t haven’t an intercept (i.e baseline), which is rare. Any reason you’re doing that here?
I’m not having any issues sampling and the model works fine. But so far I’m just setting my priors as a Normal distribution and that’s that. I would like to “know my model better”, and set different distributions to different features, do some prior/posterior predictive checks, etc.
Ah, I see. So, similar to what I did on my model, there I used Bernoulli indeed.
Exactly. And I know some of them are more linked to malicious commandlines than others. Similarly to a traditional approach where I would give more weights to these features — I would like to know how to “give them more weight”.
For example, on this application, say I have the feature invoke and the feature ls. I know by prior experience that ls is not linked to something malicious where invoke likely is. How should I set their prior distributions (or think about it), considering that?
Hmm… as I mentioned I’m very new to the statistical world, but my reasoning was: afaik the intercept represents my target variable when all features are equal to 0. In my case, if all features are set to 0, then there’s no commandline (it’s an empty string), and, by definition, cannot be malicious. Therefore I set constant = 0. Is that reasoning wrong?
That means you want the probability of a malicious flag (the Bernoulli’s probability of success) to increase when invoke increases, which means you’re expecting the coefficient on that predictor to be skewed towards positive values. You can just encode that knowledge into the mean of your Normal prior. This reasoning applies for any of the predictors you have.
Then you need to do prior and posterior predictive checks to see how (and even if) these changes affect your model and results.
More generally, I’m skeptical that you need 2K predictors to have a good model. I would encourage you to try your hand on a way more parcimonious model first. That’s because:
It’ll be much easier to reason about it (I personally can’t hold 2k predictors in my head and explain how they independently influence the probability of success).
It’ll probably make fitting more efficient – my prior is that lots of these 2k predictors are strongly auto-correlated, i.e they give you redundant information.
From a scientific standpoint, my guess for now is that you don’t need 2k predictors to explain this phenomenon
Setting constant=0 means that the probability of success in that case is expected to be 50% (because sigmoid(0) = 0.5), so that’s actually not what you want.
I would keep the intercept (it’s usually very helpful in any regression setting), and set a negative prior on it, to encode your knowledge that probability of success in those cases is close to 0. If your model infers that indeed the intercept is (very) negative, then that’s a good sign, based on your domain knowledge.
Damn… Thank you so much for your reply. It made a lot of things clear.
It feels a bit weird to fit Normal distributions to my priors since there’s no reason to believe that they are normally distributed. I definitely need to find some time to study more the base of all this.
The choice of predictors is just based on the dataset that I have… I have cleaned many words and symbols from the data but still I’m left with many different words, and when I include bigrams this number goes to ~2k.
Based on your post, I went all the way back to the data cleaning part to try and select these predictors better… The funny part was that it was taking longer to sample when I was using only words than when I included bigrams. (and I remember in one of your first episodes someone mentioned that sometimes when you include a new feature everything “makes sense” to the model and it fits much better).
I have also to look a lot into prior/posterior predictive checks. Hopefully soon I’ll get these concepts.
Well, the whole equation is going through the link function, so you’re not really using a Normal prior – only on the transformed space of the parameters, but not on the outcome space.
I know, it’s confusing. Don’t worry, it’s gonna click with time and repetition. I’d actually recommend starting with simple linear regression – your use-case is already intermediate, because there are more moving parts in a generalized regression.
I’d suggest taking a look at our Intro course – we designed it to get you from beginner to practitioner as fast and practically as possible.
Yeah, sometimes… but some other times it’s gonna be the contrary In the end, the number of regressors is just an emerging phenomenon of how you scientifically think and justify your model (what we call the “data generating process” in the Bayesian world).
Definitely. These concepts are super important, and often forgotten by beginners. That’s also why we insist on them in the Intro Course