Hello all,
I am trying out a simple toy model to infer the value of X in the following matrix-based equation
Y = AX + noise
The challenge I’ve set myself is seeing if I can push the number of dimensions/slices. In the example considered, I have 100 dimensions. A and X are square (full) matrices both with shape (100,4,4). This means that Y also has shape (100,4,4)
Here is the full code, currently running on PyMC v5.17.0. I should add that my model includes a few commented-out alternative methods for priors that l I have been experimenting with…
#%% define the observation
#Set Random Seed
np.random.seed(43)
# Set the number of slices to consider
numslices = 100
slices = np.linspace(1,numslices, numslices)
# Generate random arrays (to be inferred) with an arbitrary scaling factor
A_scale = 100
X_scale = 100
A = A_scale*np.random.random((numslices, 4, 4))
# Perform operations to set the observation
X = X_scale*np.random.random((numslices, 4, 4))
Y_true =A@X
# make the observation noisy
noise_obs = 0.5 # THIS WILL BE THE SIGMA VALUE TO BE INFERRED
noise = np.random.normal(0, noise_obs, size=Y_true.shape)
#Combine the noise and the true signal to make the observation
Y_obs = Y_true + noise
#%% pymc variables and convert arrays to pytensor values to be used in the pymc model
A_pt = pt.as_tensor_variable(A)
data_pt= pt.as_tensor_variable(Y_obs)
#%% PYMC Model
with pm.Model() as model:
#Hierarchical model based on same sigma for all values of X
# sigma = pm.HalfNormal("sigma", sigma = 1) # Hierarchical on sigma
# X_pymc = pm.Normal("X_pymc",mu=0, sigma = sigma, shape = (100,4,4))
# Non-Hierarchical Prior on 𝜎
# X_pymc = pm.Normal("X_pymc",mu=0, sigma = 1, shape = (100,4,4))
# sigma = pm.HalfNormal("sigma", sigma = 1) # Hierarchical on sigma
# Adjusted (Non-Centred) Hierarchical setup
sigma = pm.Normal("sigma", mu = 0.5, sigma=0.1)
X_raw = pm.Normal("X_raw", mu=0, sigma=1, shape=(100, 4, 4))
X_pymc = pm.Deterministic("X_pymc", X_raw * sigma)
# Prediction
Y_pymc = A_pt @ X_pymc
# Likelihood
likelihood = pm.Normal("likelihood", mu= Y_pymc, sigma=sigma, observed=data_pt)
# %% Sampling
with model:
trace = pm.sample(
draws = 1000,
tune=1000,
chains=4,
cores=4)#
# , target_accept=0.95, return_inferencedata=True
# )
# SUMMARISE AND PLOT
# %% Summarise Results - get the mean and form a matrix (like the true value of A)
summary = az.summary(trace)
X_means = summary.loc[summary.index.str.startswith("X_pymc"), "mean"].values
X_shape = (numslices, 4, 4)
X_means_matrix = X_means.reshape(X.shape)
#%%
# Plot Results (slices vs value)
fig, axes = plt.subplots(4, 4, figsize=(18, 14), sharex=True, sharey=True)
for row in range(4):
for col in range(4):
ax = axes[row, col]
ax.plot(slices, X[:, row, col], 'k',label="True", alpha=1)
ax.plot(slices, X_means_matrix[:, row, col],'r--', label="NUTS mean after sampling", alpha=1)
ax.set_title(f'C[{row+1},{col+1}]', fontsize=10 )
# ax.grid(True) # Add grid for readability
if row == 3: # X-axis labels only for the last row
ax.set_xlabel('Slice', fontsize=9)
if col == 0: # Y-axis labels only for the first column
ax.set_ylabel('Value', fontsize=9)
# Adjust the layout to create space for the legend and title
# plt.subplots_adjust(top=0.75, bottom=0.1, left=0.1, right=0.95, hspace=0.4, wspace=0.4)
plt.subplots_adjust(top=0.1, bottom=0, left=0.01, right=0.095, hspace=0.3, wspace=0.1)
# Add a shared legend above the subplots
handles, labels = axes[0, 0].get_legend_handles_labels()
fig.legend(handles, labels, loc='upper center', ncol=2, fontsize=12, frameon=True, bbox_to_anchor=(0.5, 1.0))
# Add a main title even higher above the legend
# fig.suptitle('Results (Slices vs Value)', fontsize=16, y=0.95)
plt.show()
#%% Diagnostics
# Selecting some specific indices along A_pt
subset = trace.posterior["X_pymc"].isel(
X_pymc_dim_0=0 , # Slice index
X_pymc_dim_1=0, # Row index
X_pymc_dim_2=0 # Column index
)
#Plot the chosen traces
az.plot_trace(subset)
az.plot_posterior(subset)
#trace for sigma (noise)
az.plot_trace(trace , var_names = 'sigma')
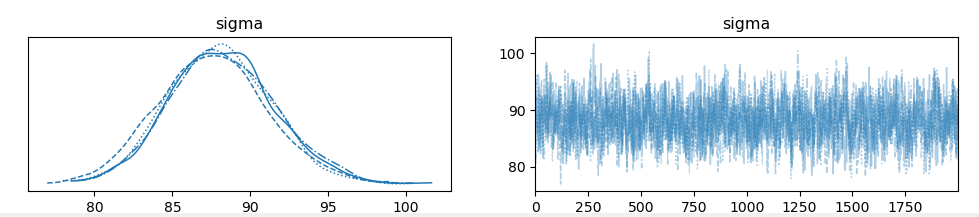
I seemed to have some joy with non-informative priors. I didn’t think it would be the best idea to plot reultant traces and distributions for such a large set of unknowns, so I have created a plot of true values (X) vs the mean of those after sampling. You can see below the inference has worked well for X but the trace and value for sigma is way off (circa 15 instead of 0.5). the Arviz summary shows the inference of sigma has poor numbers for Rhat and ESS



I have tried a number of approaches to change the likelihood and can’t seem to get an improvement in what should be the correct value of “0.5” (see noise_obs = 0.5 in the code above).
If I start adjusting the A_scale and X_scale scaling parameters in this section
# Generate random arrays (to be inferred) with an arbitrary scaling factor
A_scale = 100
X_scale = 100
A = A_scale*np.random.random((numslices, 4, 4))
# Perform operations to set the observation
X = X_scale*np.random.random((numslices, 4, 4))
Y_true =A@X
and change both A_scale and X_scale to 1, it seems to flip the issue with poorer inference of X and improved but not quite correct values of sigma. I get that is likely due to possible “signal-to-noise” issues since the standard deviation for the additive noise (0.5) sigma is close to the scaling value.
In this example, I can see from the Arviz summary that the ‘Rhat’ and ‘ESS’ for sigma are much improved, with clear normal distribution shapes, however again, the centre of the distribution is centred on the wrong value…



In summary, I would be grateful for any pointers on
- Any fundamental omissions/limitations in the code I may have simply missed.
- The use of hierarchical, non-centring or non-hierarchical approaches. Is there a method considered “best -fit” for such problems?
- Methods to extract the correct value for sigma. Particularly given the scaling could vary.
Here’s hoping someone out there can help. Thanks ![]()