Hi, I want to implement Bayesian inference on a continuous mixture model, Poisson-Beta model, which can be written as follow formula:
p|\alpha,\beta\sim Beta(\alpha,\beta)
y|\mu,p \sim Poisson(\mu\cdot p)
where \alpha, \beta, \mu are the inferred parameters. To obtain the posterior distribution of these parameters, I set the corresponding prior distribution and hyperparameters:
a\sim uniform(-2,2),b\sim uniform(-2,2)
\alpha=10^{a},\beta=10^{b}
p\sim Beta(\alpha,\beta)
\mu\sim Uniform(0,50)
y\sim Poisson(\mu\cdot p)
where the prior distributions are \alpha,\beta\sim loguniform(-2,2) and \mu\sim uniform(0,50)
First, I generate the synthetic data:
import matplotlib.pyplot as plt
import scipy.stats as stats
import numpy as np
import pandas as pd
import seaborn as sns
import pymc as pm
import arviz as az
az.style.use('arviz-darkgrid')
num_n = 1000
a_real = -0.3
b_real = -0.3
alpha_real = 10**(a_real)
beta_real = 10**(b_real)
mu_real = 20
data_p = stats.beta.rvs(alpha_real, beta_real, size = num_n)
data = stats.poisson.rvs(mu_real*data_p)
plt.figure(figsize=(4, 3))
plt.hist(data, edgecolor = 'white', density=True)
plt.xlabel('counts', fontsize = 12)
plt.ylabel('PMF', fontsize = 12)
plt.tick_params(labelsize = 10)

Second, I build the model by the pymc
rng = 111
hierarchical_model = pm.Model()
with hierarchical_model:
# Priors for unknown model parameters
a = pm.Uniform('a', lower=-2., upper=2.)
b = pm.Uniform('b', lower=-2., upper=2.)
p = pm.Beta('p', 10**a, 10**b)
mu = pm.Uniform('mu', 0, 50)
y = pm.Poisson('y', mu*p, observed=data)
idata = pm.sample_prior_predictive(samples=200, random_seed=rng)
Sampling: [a, b, mu, p, y]
However, I got the follow wrong results:
# Inference button (TM)!
with hierarchical_model:
idata.extend(pm.sample(1000, tune=2000, chains=2, random_seed=rng))
az.plot_trace(idata)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 4 jobs)
NUTS: [a, b, p, mu]
Sampling 2 chains for 2_000 tune and 1_000 draw iterations (4_000 + 2_000 draws total) took 37 seconds.
array([[<AxesSubplot: title={'center': 'a'}>,
<AxesSubplot: title={'center': 'a'}>],
[<AxesSubplot: title={'center': 'b'}>,
<AxesSubplot: title={'center': 'b'}>],
[<AxesSubplot: title={'center': 'p'}>,
<AxesSubplot: title={'center': 'p'}>],
[<AxesSubplot: title={'center': 'mu'}>,
<AxesSubplot: title={'center': 'mu'}>]], dtype=object)

with hierarchical_model:
pm.sample_posterior_predictive(idata, extend_inferencedata=True, random_seed=rng)
az.plot_ppc(idata, num_pp_samples=100)
<AxesSubplot: xlabel='y / y'>
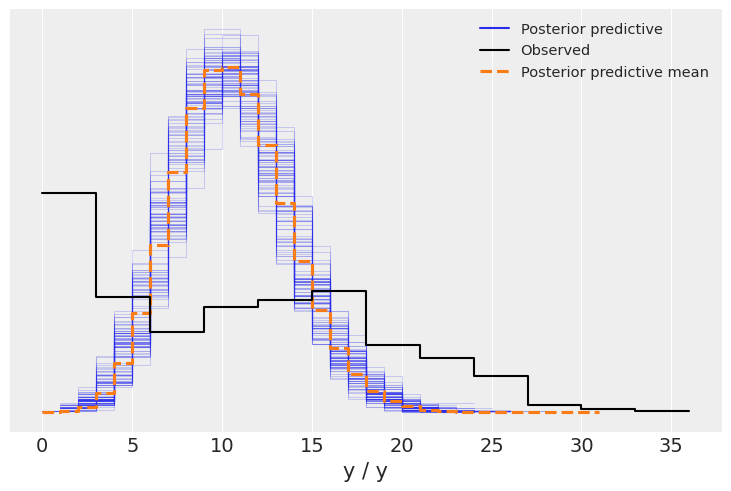
I read the section on hierarchical and mixture models and found that the Poisson-beta model is a continuous mixture model. Therefore, I raise two problems:
- I suspect that this wrong result is due to treating p as a parameter. However, p is a latent variable which is obey beta distribution. In fact, the likelihood function of poisson-beta model requires the integration of p. How do I implement this model in pymc?
- If given any finite continuous mixture model, is it possible to implement Bayesian inference in pymc?
Thanks!