This makes me wonder if there is a less computationally difficult way of achieving this. For my naive model, it’s actually quicker computationally to do a grid search than use an MCMC approach because there are many parameters which can be marginalized out analytically. It’s actually trivial to compute the marginal likelihood for each experiment through this method if I assume an uncertainty on the data points (I’ve used a value slightly higher than the measurement uncertainty is likely to be in order to capture experiments that may deviate slightly from physical assumptions but small enough that anything egregious isn’t credible). Would it be possible to use these calculated marginal likelihoods instead of the prior step in the notebook above? The hierarchical part of the model would still require MCMC as the number of experiments can be large.
As an example, here are some data with their posterior probability density calculated using this method, with the red line being the target value. There are clearly some biased experiments in this case.
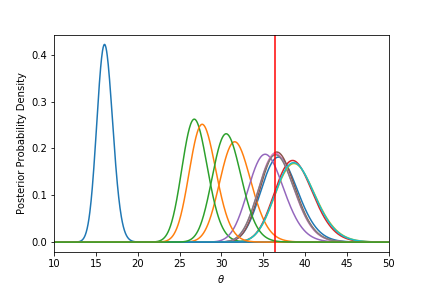
If I don’t normalize by the marginal likelihood, and instead just plot each experiment’s prior*likelihood, it becomes apparent that the biased values are extremely poorly served by this model(in some cases 40 orders of magnitude so). It seems fairly clear here that a hierarchical model with this weighting would give an unbiased result.

It’s also worth noting that the chance of failure at a population level for this experiment is not always low; in some cases the majority of experiments can be failures.